The Invisible Moat Behind the AI Empire: All About CUDA
Section 1: The Foundation of the Empire: Dissecting the CUDA Moat
NVIDIA’s powerful dominance is not just due to its exceptional semiconductor chips. The real secret lies in the ‘software moat’ that has been meticulously built over more than a decade, making it hard for anyone to overlook. In this section, we will thoroughly explore how CUDA has become the foundation of the AI revolution from both technical and strategic perspectives. I remember being amazed by its performance and the convenience of its ecosystem when I first encountered CUDA as a developer.
1.1. From Graphics to General-Purpose Computing: The Birth of CUDA
In the early days of GPU computing, developers struggled to use APIs like OpenGL or Direct3D, which were designed for graphics processing, for general-purpose computing tasks. This not only required a high level of expertise but also fell short of fully unleashing the parallel computing capabilities that GPUs truly offered.
In 2006, NVIDIA introduced CUDA (Compute Unified Device Architecture), which completely changed the game. Thanks to CUDA, developers could directly access the numerous parallel processing units of the GPU in a manner similar to the familiar C language. This was a groundbreaking event that significantly lowered the entry barrier for GPGPU (General-Purpose computing on Graphics Processing Units), marking the first step for NVIDIA in creating a massive developer-centric ecosystem.
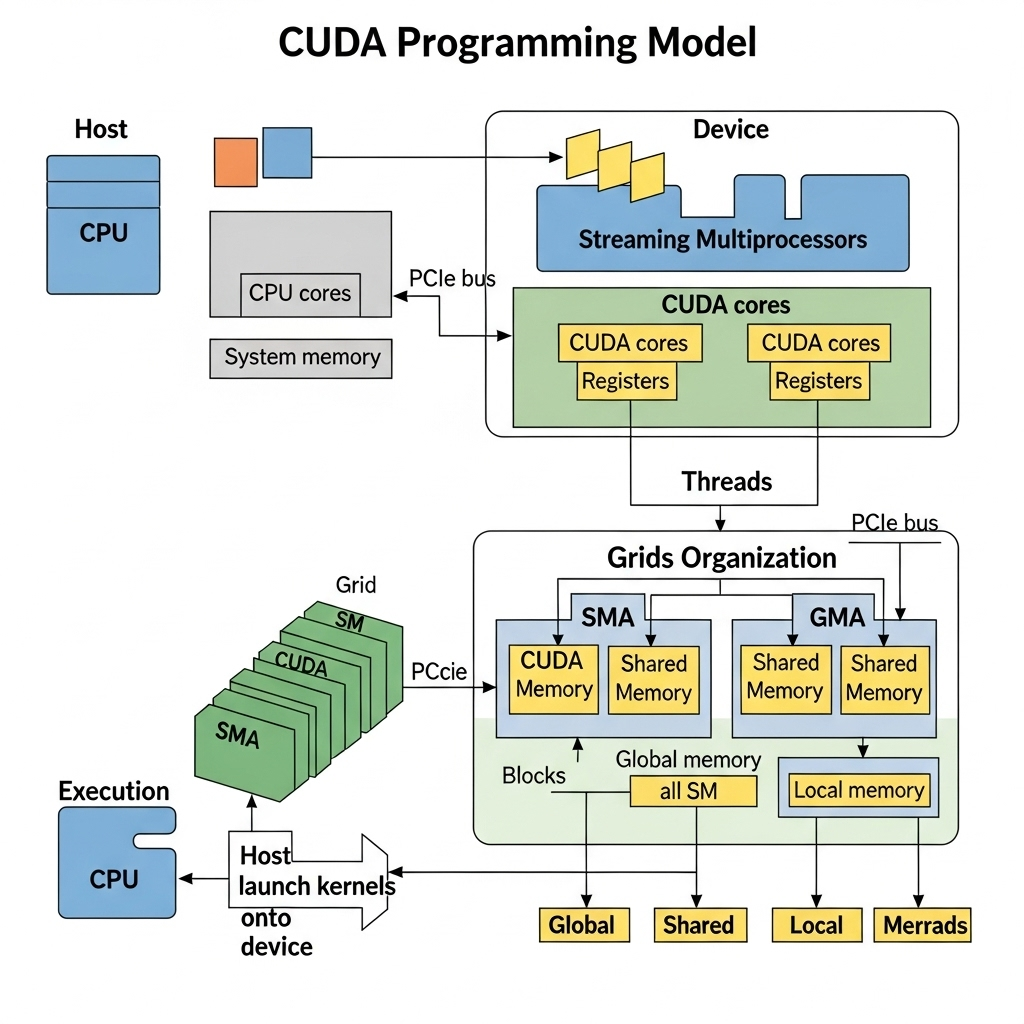
The CUDA programming model has a very clear division of roles. The main processor of the system, the CPU, acts as the ‘Host’, while the GPU, responsible for parallel operations, serves as the ‘Device’. Developers only need to define the functions to run in parallel on the GPU, known as ‘Kernels’, using the __global__ keyword. The data processing flow typically follows these steps:
- Copy data from host memory (RAM) to device memory (VRAM),
- The host (CPU) commands the device (GPU) to execute the kernel,
- The numerous cores of the GPU simultaneously execute the kernel code to process the data,
- The processed results are then brought back to the host memory.
Thanks to this simple and clear structure, developers no longer need to understand the complexities of graphic APIs to fully utilize the powerful computational capabilities of GPUs. This not only provided technical convenience but also encouraged numerous researchers and developers to dive into AI and high-performance computing (HPC).
1.2. The Technical Architecture of Lock-in: Kernels, Threads, and Memory Hierarchy
The reason CUDA is powerful and difficult to escape from once adopted lies in its technical structure. NVIDIA provides developers with sophisticated tools to extract the best performance while ensuring these tools are perfectly optimized for its hardware, naturally creating a ’lock-in effect’.
- Parallel Processing Model: CUDA manages parallel processing through a hierarchical structure of ‘Threads’, ‘Blocks’, and ‘Grids’. Threads are the smallest unit of computation, with multiple threads forming a block, and multiple blocks forming a grid. This model allows developers to efficiently distribute tasks into thousands of pieces across the thousands of cores of the GPU. This powerful model requires developers to adopt the ‘NVIDIA way’ of parallel programming, making it difficult for those accustomed to it to switch to other architectures.
- Memory Hierarchy Advantage: Another core competitive strength of CUDA lies in its sophisticated memory model. In particular, the ‘Shared Memory’ within each thread block allows for rapid data sharing, functioning like a cache managed directly by the developer. This is a key element for algorithm optimization. Additionally, features like unified virtual memory and unified memory combine CPU and GPU memory spaces, making programming easier. These features are powerful weapons unique to CUDA that competitors find hard to replicate.
- Compiler and Development Tools: NVIDIA’s compiler (NVCC) plays a crucial role in automatically separating and optimizing CPU and GPU code from CUDA code. The mature ecosystem of development tools, including debuggers and profilers, has created a gap that competitors find hard to bridge, making it a significant reason for developers to choose CUDA.
1.3. Reasons Developers Choose CUDA: Performance, Stability, and Ecosystem
The success of CUDA is not merely due to one excellent technology. It is the result of superior performance, stable APIs, a vast library, and rich documentation and community support all coming together. The difference became particularly evident in the competition against the open standard OpenCL.
OpenCL touted portability across hardware from various manufacturers as its advantage, but this actually became a hindrance. New hardware features took a long time to be reflected in the standard, and the varying levels of support and performance across manufacturers led to severe fragmentation. Developers often described their experience with OpenCL as “like hugging a cactus.”
In contrast, NVIDIA developed CUDA tightly integrated with its hardware. While this had the downside of being tied to specific hardware, it became a powerful weapon that allowed rapid addition of features to fully utilize the performance of new GPUs. NVIDIA even strategically underperformed its own OpenCL implementation to naturally guide developers towards the better-performing CUDA.
This strategy created a tremendous network effect. As more developers used CUDA, more libraries and tools emerged, creating a virtuous cycle that attracted even more developers. As AI researchers published CUDA-based code and papers, CUDA became the ’lingua franca’ of the field. Subsequent researchers had to learn CUDA to build upon existing research, further solidifying the ecosystem’s lock-in effect. Ultimately, NVIDIA’s success is a textbook case of how a long and persistent investment in developer experience can lead to overwhelming market dominance in platform economics.
Section 2: Building the Full Stack: NVIDIA’s Integrated Ecosystem Strategy
NVIDIA’s ambitions do not stop at the software moat of CUDA. They are transforming from a mere component supplier into an ’end-to-end solution’ provider encompassing everything from hardware to software and services. Let’s take a closer look at this ‘full-stack’ strategy that secures higher margins and strengthens the ecosystem.
2.1. Beyond the Core: The Role of Optimized Libraries (cuDNN, TensorRT)
NVIDIA has layered highly optimized libraries for specific fields, particularly AI, on top of CUDA. This allows developers to achieve top performance without complex low-level coding, further strengthening CUDA’s dominance.
- cuDNN (CUDA Deep Neural Network library): This library provides highly optimized primitives for core operations in deep learning, such as convolution and pooling. Popular deep learning frameworks like PyTorch and TensorFlow all use cuDNN internally to accelerate computations on NVIDIA GPUs. In effect, AI developers worldwide rely on the powerful performance of the CUDA ecosystem without even realizing it.
- TensorRT: TensorRT is an optimization tool specialized for the inference stage of deep learning. It takes trained AI models and compresses and refines them to achieve the fastest speed and maximum throughput for real service environments. TensorRT plays a decisive role in ensuring that companies cannot escape the NVIDIA ecosystem throughout the entire process from training to deployment and inference of AI models.
2.2. Turnkey Solutions: DGX Systems and “AI Supercomputers in a Box”
NVIDIA focuses not only on selling individual GPU chips but also on providing fully integrated solutions. This strategy addresses the complex infrastructure challenges faced by corporate clients all at once, allowing them to charge a high premium in return.

- History and Evolution: Starting with DGX-1 in 2016 and moving to DGX H100 and the latest DGX GB200, NVIDIA has continuously enhanced performance and integration levels in response to the explosive increase in AI computation demands.
- Strategic Rationality: DGX systems are not just servers. They have established themselves as the industry standard solution for “enterprise AI.” Each system includes the latest GPUs, NVLink for ultra-fast communication between GPUs, high-performance storage, and an optimized software stack. Thanks to this pre-configured ’turn-key’ approach, companies can reduce the time required to build and stabilize AI infrastructure from months to just a few hours. This overwhelming convenience justifies the high price and creates a strong lock-in effect at the infrastructure level.
2.3. Vertical Integration: The Strategic Importance of the Mellanox Acquisition
In 2019, NVIDIA’s acquisition of networking technology company Mellanox for $6.9 billion was the crowning achievement of its platform strategy. In modern large-scale AI data centers, networking is as crucial as GPU performance. Mellanox was a leader in InfiniBand, the standard technology in high-performance computing. This acquisition allowed NVIDIA to fully control not only the communication between GPUs within a server but also the data paths of clusters connecting numerous servers.
This vertical integration enabled proprietary technologies like GPUDirect RDMA, which allows GPUs scattered across multiple servers to exchange data directly over the network without going through the CPU. This dramatically enhances the performance of large-scale distributed learning, creating a powerful system-level competitive advantage that competitors selling only GPU chips cannot match.
2.4. Platform as a Service: AI Enterprise and DGX Cloud
NVIDIA is now expanding beyond hardware and low-level software into service-based software (SaaS) and cloud services reminiscent of Amazon Web Services (AWS), completing its full-stack vision.
- NVIDIA AI Enterprise: A comprehensive software bundle for developing, deploying, and managing AI models in enterprise environments. Sold on a subscription basis, it provides NVIDIA with stable revenue while deepening corporate clients’ dependence on the ecosystem.
- DGX Cloud: This involves moving NVIDIA’s DGX infrastructure into the data centers of major cloud service providers (CSPs) and offering it as a cloud service. This ensures that even in public cloud environments, NVIDIA’s platform is firmly established as the best for AI.
Furthermore, NVIDIA is targeting massive new markets such as industrial automation and autonomous vehicles through platforms like Omniverse for digital twins and the Isaac platform for robotics development. This shows that NVIDIA’s ecosystem is expanding beyond AI to encompass simulations and automation in the physical world.
At the pinnacle of this full-stack strategy is the recent acquisition of Run:ai, a company that creates software for virtualizing and efficiently managing GPU resources. At first glance, this technology, which enhances GPU utilization, may seem like a threat to GPU sales. However, a deeper look reveals a strategic calculation that the company controlling the ‘orchestration layer’ for allocating and managing GPU resources becomes the new gatekeeper. By directly controlling this layer, NVIDIA ensures that even when customers seek to optimize GPU usage, they do so within NVIDIA’s ecosystem. This is a clever defensive strategy to preemptively block the emergence of a third platform that could commoditize GPUs.
Section 3: Analyzing the Types of Challengers to the Fortress
What does the competitive landscape against NVIDIA’s monopoly look like? In this section, we will classify challengers based on their strategic approaches and objectively evaluate their strengths, weaknesses, and chances of success.
3.1. Mirror Strategy: AMD’s ROCm and the Journey Towards CUDA Compatibility
AMD’s core strategy is to provide an open-source alternative similar to CUDA through ROCm (Radeon Open Compute Platform). In particular, the HIP (Heterogeneous-compute Interface for Portability) API is designed to allow existing CUDA code to run on ROCm with minimal modifications, aiming to lower the transition barrier for developers.
In terms of hardware, AMD’s Instinct accelerators, especially the MI300X, are quite competitive. With a massive memory capacity of 192GB, it theoretically surpasses the specifications of NVIDIA’s H100/H200, making it advantageous for memory-intensive tasks like large language models (LLMs).
However, the critical issue lies in software. No matter how good the hardware specs are, the ROCm ecosystem is still immature, complex to install, and often buggy. Various benchmark results indicate that the performance of ROCm in its pure state, as experienced by general users, falls short of expectations, and achieving peak performance often requires specialized software supported by AMD engineers. This ‘software gap’ is the fundamental reason why AMD cannot convert its excellent hardware into actual market share.
Table 1: Summary of LLM Workload Performance Benchmarks: NVIDIA H200 vs AMD MI300X
| Category | NVIDIA H200 (CUDA) | AMD MI300X (ROCm) |
|---|---|---|
| Memory Capacity | 141GB HBM3e | 192GB HBM3 (Advantage) |
| LLM Inference Throughput | Advantage (TensorRT-LLM) | Disadvantage (vLLM) |
| LLM Training Throughput | Advantage | Disadvantage |
| Large-Scale Scalability | Overwhelming Advantage (NCCL) | Serious Disadvantage (RCCL) |
| Software Maturity | Very High | Low (Unstable, Bugs) |
In conclusion, while the MI300X has competitive advantages in specific inference tasks due to its ample memory, it significantly lags behind NVIDIA in training performance and especially in large-scale scalability due to the immaturity of its software and networking ecosystem. NVIDIA’s next-generation chip, Blackwell (B200), is expected to widen this gap further.
3.2. The Bet on Open Standards: Intel’s oneAPI and Vendor Neutrality
Intel’s oneAPI takes a different path from AMD. Based on open standards like SYCL, it is designed to work across various accelerators from different manufacturers, including CPUs, GPUs, and FPGAs. The core value of oneAPI is the liberation from ‘vendor lock-in’ associated with specific companies.
However, like ROCm, oneAPI faces the challenge of still being in the early stages compared to CUDA. It has a long way to go in terms of library support, documentation, and hardware-specific performance optimization. While theoretically portable, achieving the best performance still requires tuning for specific hardware. Currently, Intel ranks third in the AI accelerator market, and oneAPI can be seen as a long-term bet on a future where open standards are valued more than proprietary solutions. Its success will depend on the performance of Intel’s own accelerators (e.g., Gaudi) and the extent to which the oneAPI standard is widely adopted in the industry.
3.3. The Threat of Abstraction: Can Triton and Mojo Render Hardware Irrelevant?
Perhaps the most powerful and long-term threat to NVIDIA comes from ‘abstraction layers’ that could reduce hardware to mere components. These have the potential to shake the foundations of CUDA’s moat.
- OpenAI’s Triton: Triton is a Python-based language for writing high-performance GPU kernels. The core idea is that when developers write code with easy syntax similar to NumPy, the Triton compiler automatically handles complex low-level optimizations like memory management. Triton’s goal is to achieve CUDA-level performance with Python-level productivity. Crucially, Triton is open-source and supports both NVIDIA and AMD backends.
- Modular’s Mojo: Mojo is a new programming language that combines the convenience of Python with the performance of C++/Rust. Based on the technology of MLIR, it is designed from the ground up to support various hardware, including CPUs and GPUs, without relying on CUDA. Mojo’s ultimate goal is to provide a single language for all AI development, solving the ’two-language problem’ where high-level logic is written in Python and low-level optimizations in C++/CUDA.
- Existential Threat: Both Triton and Mojo directly attack the foundation of CUDA’s moat. If developers can achieve optimal performance on all GPUs (NVIDIA, AMD, Intel) with a single code written in Python or Mojo, hardware would become interchangeable components. This would dismantle CUDA’s lock-in and weaken NVIDIA’s platform-based pricing power, forcing it to compete solely on hardware performance. This represents an attempt to change the rules of the game, and sometimes, competitors who change the rules can be more dangerous than those who simply play the game better.
Table 2: Comparative Analysis of GPGPU Software Platforms
| Attribute | CUDA | ROCm (HIP) | oneAPI (SYCL) | Triton | Mojo |
|---|---|---|---|---|---|
| Programming Model | C++ Extension, Proprietary | C++ Based, CUDA Similar | C++ Based, Open | Python Based | Python Superset |
| Hardware Support | NVIDIA Only | AMD (Main), NVIDIA | Vendor Neutral | NVIDIA, AMD | Vendor Neutral Goal |
| Ecosystem Maturity | Very High | Medium | Low | Medium | Very Low |
| Core Strengths | Performance, Stability | Open Source | Vendor Neutrality | High Productivity | Python Compatibility |
| Core Weaknesses | Vendor Lock-in | Instability | Lack of Ecosystem | Limited Applicability | Early Stage |
Section 4: The Weight of the Crown: Global Antitrust Regulatory Pressures
NVIDIA’s overwhelming dominance has inevitably attracted the scrutiny of regulatory authorities worldwide. In this section, we will analyze how various regulatory bodies are targeting NVIDIA’s core success strategy, the CUDA moat, with legal reasoning.
4.1. United States: DOJ’s Investigation into Tying, Bundling, and Exclusive Practices
The U.S. Department of Justice (DOJ) is zeroing in on the heart of NVIDIA’s platform strategy. The key allegations in the investigation include:
- Illegal Tying and Bundling: Allegations that by selling its dominant product, GPUs, NVIDIA illegally ties its own software and services, such as CUDA, thereby locking customers into its ecosystem and stifling competition.
- Exclusive Dealing: Whether NVIDIA provides benefits in terms of pricing, volume, and technical support to customers who exclusively use its products, disadvantaging those who use competitors’ products.
4.2. European Union (EU) and France: Focus on Abuse of Market Dominance and Unfair Competition
French competition authorities are leading the investigation into NVIDIA under the EU’s oversight. They explicitly point out that “the bundling of CUDA and chips is potentially anti-competitive,” raising issues of price collusion, supply restrictions, and unfair contract terms. If the allegations are upheld, NVIDIA could face massive fines of up to 10% of its annual revenue.
4.3. China’s Leverage: Antitrust Regulation as a Geopolitical Tool
China has also initiated its own antitrust investigation. This investigation focuses on whether NVIDIA abuses its market share of over 90% by bundling GPUs with the InfiniBand networking technology obtained through the Mellanox acquisition, thereby limiting the performance of third-party networking solutions. This can also be interpreted as a geopolitical card for China to secure leverage against U.S. advanced chip export controls.

4.4. The Run:ai Acquisition: A Case Study of Strategic Acquisitions to Suppress Competition
NVIDIA’s acquisition of Run:ai is a key focus of regulatory scrutiny. The logic of the allegations is very sophisticated. It is argued that NVIDIA did not acquire Run:ai to integrate its technology but rather to ‘suppress’ technology that makes GPU usage more efficient. If GPU usage is optimized, customers would buy fewer GPUs, impacting NVIDIA’s revenue, thus preemptively eliminating this threat. This allegation could be very damaging as it portrays NVIDIA not just as an expensive monopolist but as a company actively hindering technological advancement.
Table 3: Overview of Global Antitrust Investigations Against NVIDIA
| Jurisdiction | Key Allegations | Core Investigation Targets |
|---|---|---|
| United States (DOJ) | Tying, Exclusive Dealing, Anti-competitive Acquisitions | CUDA Bundling, Run:ai Acquisition, Customer Discrimination |
| EU / France | Abuse of Market Dominance, Price Collusion, Supply Restrictions | Bundling of CUDA and Hardware |
| China (SAMR) | Abuse of Market Dominance (Bundling), Fair Trading Violations | Bundling of GPUs and InfiniBand Technology |
Section 5: NVIDIA’s Counterattack: Roadmap, Vision, and Strategic Concessions
Of course, NVIDIA is not sitting idly by. They are actively defending their dominance through faster product release cycles, a strong future vision, and sophisticated ‘strategic openness’ moves to neutralize threats.
5.1. Accelerating the One-Year Cadence: Blackwell, Rubin, and Beyond
NVIDIA recently announced plans to shorten its new product release cycle from two years to one year. This is a deliberate strategy to make it impossible for competitors to catch up. The announced roadmap includes Hopper (2022), Blackwell (2024), and Rubin (2026), signaling the evolution of a complete platform that encompasses not only GPUs but also CPUs and networking. This aggressive pace aims to continue widening the performance gap with competitors while ensuring the entire market revolves around NVIDIA’s roadmap, effectively relegating competitors to eternal pursuers.
5.2. “AI Factory”: NVIDIA’s Vision for the Future of Enterprise Computing
NVIDIA is selling not just hardware but a single ‘vision.’ This vision is that, just as companies build factories to produce goods, in the future, they will have AI factories, or data centers, to produce intelligence.
This vision positions NVIDIA’s products, such as DGX and AI Enterprise, as essential facilities for a new industrial revolution. It justifies massive investments in its platform by positioning NVIDIA as a fundamental partner in corporate innovation.
5.3. Open Source Defense Strategy: Selective Openness
In response to antitrust pressures and the rise of open-source challengers, NVIDIA has launched a sophisticated ‘strategic openness’ campaign. This is not about abandoning its proprietary model but rather a calculated move to defuse criticism and embrace threats.
NVIDIA has strategically open-sourced certain components, such as Linux driver kernel modules and the recently acquired Run:ai software. This aims to avoid accusations of being a closed monopolist while shifting the responsibility onto competitors by suggesting, “If you want to use it on AMD hardware, you develop it yourself.” Of course, the most fully supported version will be NVIDIA’s. The core CUDA compiler and GPU hardware design remain firmly as proprietary assets, while less critical assets are relinquished to protect the core in a sophisticated diversion strategy.
Conclusion
We have explored how NVIDIA’s CUDA platform has established itself as the absolute leader in the AI era and the challenges it faces. NVIDIA’s future will be determined by the interaction of four forces.
-
Core Summary:
- Strong Moat: CUDA is not just software; it is an overwhelming ecosystem that includes over a decade of accumulated libraries, development tools, and community.
- Types of Challenges: Beyond direct competition from AMD and Intel, abstraction layers like Triton/Mojo pose a more fundamental threat that could dismantle CUDA’s lock-in effect.
- Future Scenarios: NVIDIA’s dominance may continue (The Moat Holds), but it could weaken due to abstraction layers (The Moat Erodes) or collapse under strong antitrust regulations (The Moat is Breached).
In the medium term, NVIDIA’s dominance is likely to be maintained to a significant extent, but the open-source-based ‘open abstraction’ movement will be the biggest variable in the long run. What do you think will happen to NVIDIA’s monopoly in the future?
References
- CUDA Concepts and Beginner Examples (1/2) - MangKyu’s Diary Link
- CUDA - Wikipedia, the free encyclopedia Link
- What is CUDA and Why Use It? - My Dream is Automation Link
- The CUDA Empire - Medium Link
- CUDA vs OpenCL - Andreas Klöckner’s Former Wiki Link
- What about OpenCL and CUDA C++ alternatives? - Modular Blog Link
- Accelerating Transformers with NVIDIA cuDNN 9 - NVIDIA Developer Blog Link
- What is TensorRT? - OPAC Link
- NVIDIA DGX Systems - BNINC Link
- NVIDIA Mergers and Acquisitions and Business Growth Strategy - acqu1esce’s Blog Link
- “No longer just a chip company”… NVIDIA resembling Amazon, what about its platform strategy? - Edaily Link
- Department of Justice Begins Antitrust Probe into Nvidia - HPCwire Link
- A Comprehensive Guide: Switching from CUDA to ROCm - TensorWave Link
- MI300X vs H100 vs H200 Benchmark Part 1: Training – CUDA Moat Still Alive - SemiAnalysis Link
- oneAPI: A Viable Alternative To CUDA* Lock-in - Intel Link
- Introducing Triton: Open-source GPU programming for neural networks - OpenAI Link
- Welcome to Triton’s documentation! Link
- Mojo: Powerful CPU+GPU Programming - Modular Link
- The DOJ and Nvidia: AI Market Dominance and Antitrust Concerns - AAF Link
- Reuters: “France to impose sanctions for NVIDIA antitrust violations” - Hankyoreh Link
- Key Analysis of China’s Antitrust Investigation into Nvidia - Ming-Chi Kuo Link
- Highlights from the ‘GTC 2025’ overflowing with news - NVIDIA Blog Korea Link
- NVIDIA Transitions Fully Towards Open-Source GPU Kernel Modules - NVIDIA Developer Blog Link