建造AI帝国的无形护城河:CUDA全解析
第一章:帝国的基石:CUDA护城河解析
英伟达之所以能占据主导地位,并非仅仅因为其卓越的芯片。更重要的是,它耗费十余年时间构建了一道难以逾越的“软件护城河”。本章将从技术和战略层面,深入剖析CUDA是如何成为AI革命基石的。
1.1. 从图形处理到通用计算:CUDA的诞生
在GPU计算的早期,开发者们不得不费力地将为图形处理设计的OpenGL或Direct3D等API,强行用于通用计算任务。这不仅需要高深的技术知识,而且难以完全发挥GPU的并行计算潜力。
2006年,英伟达推出了具有划时代意义的CUDA(Compute Unified Device Architecture)。CUDA让开发者能够以类似C语言的熟悉方式,直接访问GPU的海量并行处理单元。这极大地降低了**GPGPU(General-Purpose computing on Graphics Processing Units)**的门槛,标志着英伟达开始构建以开发者为中心的庞大生态系统。
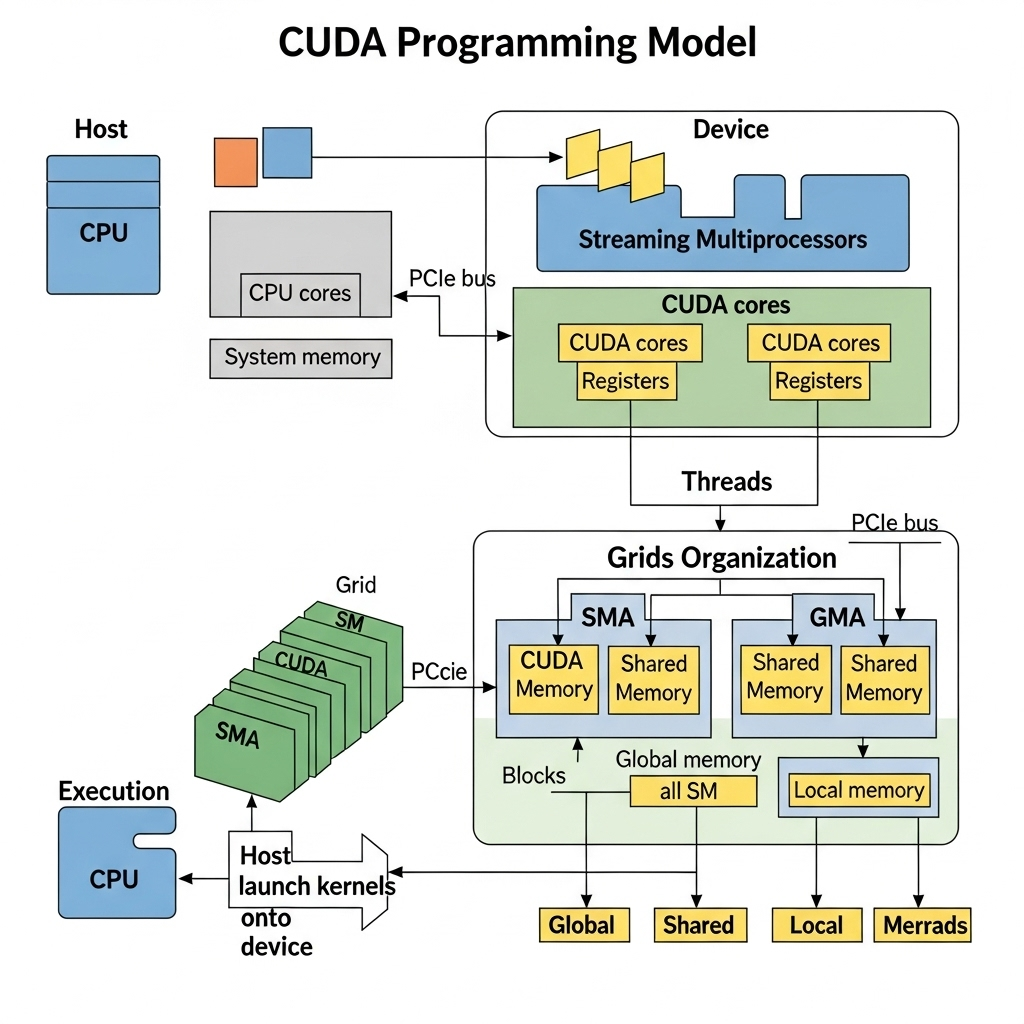
CUDA的编程模型职责分工明确。CPU作为主处理器,被称为**“Host”;负责并行计算的GPU则称为“Device”。开发者只需使用__global__关键字定义要在GPU上运行的函数,即“Kernel”**。数据处理流程通常是:
- 将数据从Host内存(RAM)复制到Device内存(VRAM)。
- Host(CPU)指令Device(GPU)执行Kernel。
- GPU的众多核心同时执行Kernel代码,处理数据。
- 将处理结果返回Host内存。
这种简单明了的结构,让开发者无需了解复杂的图形API细节,就能充分利用GPU强大的计算能力。这不仅带来了技术上的便利,也促使大量研究者和开发者投身AI和高性能计算(HPC)领域。
1.2. 锁定(Lock-in)的技术架构:Kernel、线程与内存层级
CUDA之所以强大且难以摆脱,原因在于其技术结构本身。英伟达提供了能最大化性能的精巧工具,并确保这些工具完美适配自家硬件,从而自然地产生了**“锁定效应”**。
- 并行处理模型: CUDA通过**“Thread”、“Block”和“Grid”**的层级结构来管理并行处理。线程是最小的计算单元,多个线程组成一个Block,多个Block组成一个Grid。这种模型使开发者能将任务分解为数万个,并高效地分配给GPU的数千个核心。这种模型要求开发者采用“英伟达式”的并行编程思维,一旦习惯,就很难转向其他架构。
- 内存层级的优势: CUDA的另一个核心竞争力在于其精密的内存模型。特别是,**“Shared Memory”**允许同一线程块内的线程以极高的速度共享数据,如同用户管理的缓存。这是算法优化的关键。此外,统一虚拟内存和统一内存等功能将CPU和GPU的内存空间融为一体,简化了编程。这些功能是CUDA独有的强大武器,竞争平台难以轻易复制。
- 编译器和开发工具: 英伟达的编译器(NVCC)能自动分离和优化CUDA代码中的CPU和GPU部分。配合多年打磨的成熟开发工具(如调试器、性能分析器),与竞争对手拉开了显著差距,成为开发者选择CUDA的重要原因。
1.3. 开发者选择CUDA的原因:性能、稳定性和生态系统
CUDA的成功并非仅凭单一技术。它是卓越性能、稳定API、海量库以及丰富文档和社区支持共同作用的结果。与开放标准OpenCL的竞争尤其凸显了其优势。
OpenCL以能在多厂商硬件上运行的通用性为卖点,但这反而成了其劣势。新硬件功能的标准更新缓慢,各厂商支持水平和性能参差不齐,导致碎片化严重。开发者曾戏称使用OpenCL的体验“像抱仙人掌一样”。
相反,英伟达将CUDA与自家硬件紧密结合。尽管存在硬件依赖的缺点,但这成为其强大武器,能够快速为新GPU添加充分发挥性能的功能。英伟达甚至故意弱化自家OpenCL的实现,引导开发者自然转向性能更优的CUDA。
这种策略产生了巨大的网络效应:越多的开发者使用CUDA,就越多的库和工具涌现,这又吸引了更多开发者,形成良性循环。AI研究者发布基于CUDA的代码和论文,使CUDA成为该领域的**“通用语言”**。后来的研究者为了延续现有研究,不得不学习CUDA,进一步巩固了生态系统的锁定效应。最终,英伟达的成功是开发者体验上的长期、专注投入如何转化为压倒性市场主导力的平台经济学经典案例。
第二章:全栈(Full Stack)构建:英伟达的整合生态系统战略
英伟达的野心不止于CUDA软件护城河。它正从单纯的零部件供应商,转型为涵盖硬件、软件和服务的**“端到端(end-to-end)解决方案”**提供商。这种旨在提高利润率和增强生态粘性的“全栈”战略,其宏大蓝图值得我们仔细审视。
2.1. 超越核心:优化库的作用(cuDNN, TensorRT)
英伟达在CUDA之上,为特定领域(尤其是AI)叠加了一层层高度优化的库。这使得开发者无需复杂的底层编码,就能轻松获得最佳性能,进一步巩固了CUDA的主导地位。
- cuDNN (CUDA Deep Neural Network library): 该库以“原始(primitive)”形式提供了高度优化的深度学习核心运算,如卷积和池化。PyTorch和TensorFlow等主流深度学习框架在内部都使用cuDNN来加速英伟达GPU上的运算。实际上,全球AI开发者在不知不觉中都在依赖CUDA生态系统的强大性能。
- TensorRT: TensorRT是专门为深度学习**“推理(inference)”**阶段优化的工具。它接收训练好的AI模型,进行压缩和精简,以实现最高速度和最大吞吐量。TensorRT在AI模型从训练到部署、推理的整个流程中,起到了关键作用,使企业难以脱离英伟达生态。
2.2. 整体解决方案:DGX系统与“盒装AI超级计算机”
英伟达不仅仅销售独立的GPU芯片,而是专注于销售完全集成的解决方案。他们通过一站式解决企业客户复杂的基础设施搭建问题,并从中获得高额溢价。

- 历史与演进: 从2016年的DGX-1开始,到DGX H100,再到最新的DGX GB200,英伟达随着AI计算需求的爆炸式增长,不断提升性能和集成度。
- 战略合理性: DGX系统并非简单的服务器。“企业级AI行业标准解决方案”的定位十分明确。每个系统都包含最新GPU、用于GPU间超高速通信的NVLink、高性能存储,以及优化的软件栈。这种预配置的**“整体(turn-key)”**模式,使企业能将AI基础设施的搭建和稳定时间从数月缩短到数小时。这种压倒性的便利性,为其高昂价格提供了依据,并在基础设施层面创造了强大的锁定效应。
2.3. 垂直整合:收购Mellanox与网络的重要性
2019年,英伟达斥资69亿美元收购了网络技术公司Mellanox,这是其平台战略的点睛之笔。因为在现代大规模AI数据中心,网络的重要性与GPU性能不相上下。Mellanox是高性能计算领域标准技术InfiniBand的领导者。通过此次收购,英伟达得以完全控制服务器内部GPU间的通信,以及连接众多服务器的整个集群的数据通路。
这种垂直整合促成了GPUDirect RDMA等专有技术,使分布在多台服务器上的GPU无需通过CPU,就能直接通过网络交换数据。这极大地提升了大规模分布式训练的性能,并为英伟达创造了单纯销售GPU芯片的竞争对手难以企及的强大系统级竞争优势。
2.4. 平台即服务:AI Enterprise与DGX Cloud
如今,英伟达正通过服务型软件(SaaS)和云服务,将业务从硬件和底层软件扩展到类似亚马逊AWS的平台,完成了全栈愿景。
- NVIDIA AI Enterprise: 这是企业级AI模型开发、部署和管理的一套全面软件套件。以订阅方式销售,为英伟达带来稳定收入,同时深化了企业客户对英伟达生态的依赖。
- DGX Cloud: 将英伟达的DGX基础设施直接部署到主流云服务提供商(CSP)的数据中心,并以云服务形式提供。借此,英伟达在公共云环境中也牢牢确立了“最佳AI平台是英伟达的”的地位。
此外,英伟达还通过数字孪生的Omniverse、机器人开发的Isaac平台等,进军工业自动化、自动驾驶等新兴巨头市场。这表明英伟达的生态系统正从AI扩展到物理世界的模拟和自动化。
本次Run:ai收购是其全栈战略的又一高潮。Run:ai是一家开发GPU资源虚拟化和高效管理软件的公司。表面上看,提高GPU利用率的技术似乎会减少GPU销量。但深层来看,掌握GPU资源分配和管理**“编排层(orchestration layer)”**的公司将成为新的守门人。英伟达通过直接控制这一层,确保客户即使在优化GPU使用时,也始终在英伟达生态系统内。这是一种极为精明的防御策略,旨在阻止第三方平台将GPU变成普通商品。
第三部分:堡垒攻坚:挑战者类型分析
英伟达的垄断地位,竞争格局如何?本节将根据策略,对挑战者进行分类,并客观评估它们的优劣势和成功可能性。
3.1. 镜像策略:AMD 的 ROCm 与 CUDA 兼容之路
AMD 的核心策略是推出 ROCm (Radeon Open Compute Platform),一个类似 CUDA 但开源的替代方案。特别是 HIP (Heterogeneous-compute Interface for Portability) API,旨在让开发者只需稍作修改即可在 ROCm 上运行现有 CUDA 代码,从而降低迁移门槛。
硬件方面,AMD 的 Instinct 加速器,尤其是 MI300X,竞争力很强。其高达 192GB 的内存容量,超过了英伟达 H100/H200,理论上在需要大量内存的大语言模型(LLM)等任务中更具优势。
然而,关键问题在于软件。即使硬件规格再好,ROCm 生态系统仍不成熟,安装复杂,并且存在大量 bug。许多基准测试显示,普通用户使用原生 ROCm 时性能不达预期,而要达到最佳性能,往往需要 AMD 工程师特别支持的专用软件。这种 “软件差距” 是 AMD 无法将其卓越硬件转化为实际市场份额的根本原因。
表 1:LLM 工作负载性能基准摘要:NVIDIA H200 vs AMD MI300X
| 类别 | NVIDIA H200 (CUDA) | AMD MI300X (ROCm) |
|---|---|---|
| 内存容量 | 141GB HBM3e | 192GB HBM3 (占优) |
| LLM 推理吞吐量 | 占优 (TensorRT-LLM) | 劣势 (vLLM) |
| LLM 训练吞吐量 | 占优 | 劣势 |
| 大规模扩展性 | 压倒性优势 (NCCL) | 严重劣势 (RCCL) |
| 软件成熟度 | 非常高 | 低(不稳定,bug 多) |
总而言之,MI300X 因其充足的内存,在特定推理任务中具有竞争力。但在训练性能以及多 GPU 并联的大规模扩展性方面,由于软件和网络生态系统的不成熟,仍与英伟达差距甚远。英伟达的下一代芯片 Blackwell (B200) 预计将进一步拉大这一差距。
3.2. 开放标准致胜:Intel 的 oneAPI 与对供应商中立性的押注
Intel 的 oneAPI 走了不同的道路。它基于 SYCL 等开放标准,是一个统一的编程模型,设计用于在 CPU、GPU、FPGA 等不同制造商的各种加速器上运行。oneAPI 的核心价值在于 摆脱对特定公司的“供应商锁定”。
然而,oneAPI 也面临像 ROCm 类似的挑战,其生态系统仍处于早期阶段,与 CUDA 相比还有差距。在库支持、文档和硬件性能优化方面,它还有很长的路要走。理论上具有很高的可移植性,但实际要达到最佳性能,仍需针对不同硬件进行调优。目前 Intel 是 AI 加速器市场的第三大玩家,oneAPI 是对未来开放标准比专有解决方案更有价值的一种长期投资。其成功取决于 Intel 自家加速器(如 Gaudi)的性能以及 oneAPI 标准在行业中的普及程度。
3.3. 抽象化的威胁:Triton 和 Mojo 能让硬件变得无关紧要吗?
对英伟达最强大、最持久的威胁,可能来自于那些能将硬件简化为“零件”的 “抽象层(abstraction layer)”。它们有潜力动摇 CUDA 护城河的根基。
- OpenAI 的 Triton: Triton 是一个基于 Python 的语言,用于编写高性能 GPU 内核。其核心在于,开发者用类似 NumPy 的简单语法编写代码,Triton 编译器会自动处理内存管理等专家级复杂底层优化。Triton 的目标是用 Python 的生产力来实现 CUDA 级别的性能。最关键的是,Triton 是开源的,并支持 NVIDIA 和 AMD 的后端。
- Modular 的 Mojo: Mojo 是一种新的编程语言,结合了 Python 的便利性和 C++/Rust 的性能。它基于 MLIR 技术,从一开始就设计为支持 CPU、GPU 等各种硬件,而不依赖 CUDA。Mojo 的最终目标是为整个 AI 开发提供一种单一语言,解决当前高层逻辑用 Python、底层优化用 C++/CUDA 的“双语言问题”。
- 生存威胁: Triton 和 Mojo 都直接攻击 CUDA 护城河的基础。如果开发者用一套用 Python 或 Mojo 编写的代码就能在所有 GPU(NVIDIA、AMD、Intel)上获得最佳性能,那么硬件将变得可互换。这将打破 CUDA 的锁定,迫使英伟达仅凭硬件性能竞争,削弱其平台驱动的价格制定能力。这是一种试图改变现有游戏规则的尝试,有时改变游戏规则的竞争者比试图玩好游戏的竞争者更危险。
表 2:GPGPU 软件平台比较分析
| 属性 | CUDA | ROCm (HIP) | oneAPI (SYCL) | Triton | Mojo |
|---|---|---|---|---|---|
| 编程模型 | C++ 扩展,专有 | C++ 为基础,类似 CUDA | C++ 为基础,开放 | Python 为基础 | Python 超集 |
| 硬件支持 | 仅限 NVIDIA | AMD (为主),NVIDIA | 供应商中立 | NVIDIA,AMD | 目标是供应商中立 |
| 生态系统成熟度 | 非常高 | 中等 | 低 | 中等 | 非常低 |
| 核心优势 | 性能,稳定性 | 开源 | 供应商中立性 | 高生产力 | Python 兼容性 |
| 核心劣势 | 供应商锁定 | 不稳定性 | 生态系统不足 | 应用范围有限 | 初级阶段 |
第四部分:王冠的重量:全球反垄断监管压力
英伟达的压倒性统治地位,必然引来全球监管机构的审视。本节将深入分析各国监管机构如何从法律角度,瞄准英伟达的核心成功战略——CUDA 护城河。
4.1. 美国:司法部 (DOJ) 调查捆绑销售、打包销售和排他性行为
美国司法部 (DOJ) 正将目标对准英伟达平台战略的核心。调查的主要指控包括:
- 非法捆绑 (Tying) 和打包销售 (Bundling): 指控其以主导产品 GPU 为诱饵,非法捆绑自家软件和服务(如 CUDA),将客户锁定在生态系统中,阻碍竞争。
- 排他性交易 (Exclusive Dealing): 调查其是否通过给予独家使用英伟达产品的客户价格、数量、技术支持等方面的优惠,从而对同时使用竞争对手产品的客户施加不利影响。
4.2. 欧盟 (EU) 和法国:聚焦滥用市场支配地位和不公平竞争
在欧盟整体监管的关注下,法国竞争监管机构主导了对英伟达的调查。他们明确指出“CUDA 与芯片的捆绑可能具有反竞争性质”,并质疑价格垄断、供应限制和不公平的合同条款。一旦指控成立,可能面临高达年收入 10% 的巨额罚款。
4.3. 中国的筹码:作为地缘政治工具的反垄断监管
中国也已启动反垄断调查。调查重点在于英伟达是否滥用其超过 90% 的市场份额,将 GPU 与通过收购 Mellanox 获得的 InfiniBand 网络技术打包销售,并限制第三方网络解决方案的性能。这也被解读为中国为对抗美国高端芯片出口管制,争取谈判筹码的地缘政治策略。

4.4. 收购 Run:ai:遏制竞争的战略收购案例研究
英伟达收购 Run:ai 是监管机构调查的重点。其指控逻辑十分精妙:声称英伟达收购 Run:ai 并非为了整合其技术,而是为了“扼杀”能够提高 GPU 使用效率的技术。因为 GPU 使用效率的提高会降低客户对 GPU 的需求,从而损害英伟达的销售额,因此英伟达提前消除了这种威胁。这一指控极具破坏力,因为它将英伟达描绘成一个不仅价格昂贵的垄断者,而且是积极阻碍技术进步的企业。
表 3:全球对英伟达的反垄断调查概览
| 管辖区 | 主要指控 | 调查重点 |
|---|---|---|
| 美国 (DOJ) | 捆绑销售,排他性交易,反竞争收购 | CUDA 打包,Run:ai 收购,客户歧视 |
| EU / 法国 | 滥用市场支配地位,价格垄断,供应限制 | CUDA 与硬件捆绑 |
| 中国 (SAMR) | 滥用市场支配地位(捆绑销售),违反公平竞争 | GPU 与 InfiniBand 技术捆绑 |
第五部分:英伟达的反击:路线图,愿景与战略让步
当然,英伟达并非坐以待毙。他们通过加快产品发布周期,展示强大的未来愿景,以及精心设计的“战略开放”策略来化解威胁,积极防御其统治地位。
5.1. 加速一年周期(Cadence):Blackwell、Rubin 及更远
英伟达近期宣布将新产品发布周期从两年缩短至一年。这是一种故意的策略,旨在让竞争对手难以追赶。已公布的路线图包括 Hopper (2022)、Blackwell (2024)、Rubin (2026),预示着一个涵盖 GPU、CPU 和网络在内的完整平台进化。这种激进的速度旨在持续拉大与竞争对手的性能差距,同时迫使整个市场围绕英伟达的路线图运转,让竞争对手永远扮演追赶者的角色。
5.2. “AI 工厂”:英伟达对企业计算未来的愿景
英伟达销售的不仅是硬件,更是一种“愿景”。这就是“AI 工厂”的概念。就像企业建造工厂来生产产品一样,未来将拥有 AI 工厂,也就是数据中心,来生产智能。
这一愿景将英伟达的 DGX 和 AI Enterprise 等产品定位为新一轮工业革命的必备设备。这是一个强大的营销叙事,将英伟达定位为企业创新的根本合作伙伴,并为其平台上的巨额投资提供了理由。
5.3. 开源防御策略:选择性开放
面对反垄断压力和开源挑战者的崛起,英伟达发起了一项名为“战略性开放”的精巧宣传活动。这并非放弃垄断模式,而是经过深思熟虑的举动,旨在平息批评并应对威胁。
英伟达战略性地开源了部分组件,例如 Linux 驱动程序的内核模块,以及最近收购的 Run:ai 软件。此举一方面避免了被指责为封闭的垄断企业,另一方面则将责任推给了竞争对手,让它们自行开发,如果想在 AMD 硬件上运行,就得自己动手。当然,最完美的兼容版本还是英伟达自己的。最核心的 CUDA 编译器和 GPU 硬件设计仍然牢牢掌握在手中,这是通过让出非核心资产来保护核心的精妙策略。
结论
至此,我们探讨了英伟达的 CUDA 平台如何成为 AI 时代的绝对领导者,以及它面临哪些挑战。英伟达的未来将取决于四种力量的相互作用。
-
核心要点:
- 坚固的壁垒: CUDA 不仅仅是软件,它是一个拥有十多年积累的库、开发工具和社区的压倒性生态系统。
- 挑战类型: 除了 AMD 和 Intel 的直接竞争,像 Triton/Mojo 这样的硬件抽象层是更根本的威胁,它们有可能打破 CUDA 的锁定效应。
- 未来情景: 英伟达的统治地位可能会继续(壁垒得以维持),但可能会因抽象层的出现而减弱(壁垒被侵蚀),或者因强力的反垄断监管而崩溃(壁垒被攻破)。
中期来看,英伟达的统治地位将在很大程度上得以维持,但基于开源的“开放抽象”运动将是长期最大的变数。您认为英伟达的垄断地位未来将如何演变?
参考资料
- CUDA 概念及 CUDA 入门示例 (1/2) - MangKyu’s Diary 链接
- CUDA - 维基百科,自由的百科全书 链接
- 什么是 CUDA,为什么使用它?- My Dream is Automation 链接
- The CUDA Empire - Medium 链接
- CUDA vs OpenCL - Andreas Klöckner’s Former Wiki 链接
- What about OpenCL and CUDA C++ alternatives? - Modular Blog 链接
- 加速 Transformer 模型:NVIDIA cuDNN 9 - NVIDIA Developer Blog 链接
- 什么是 TensorRT?- OPAC 链接
- NVIDIA DGX 系统 - BNI&C 链接
- 英伟达 (NVIDIA) 并购 (M&A) 及业务增长战略 - acqu1esce’s Blog 链接
- “不再是芯片公司了”… 像亚马逊一样发展的英伟达,平台战略是什么?- eDaily 链接
- Department of Justice Begins Antitrust Probe into Nvidia - HPCwire 链接
- A Comprehensive Guide: Switching from CUDA to ROCm - TensorWave 链接
- MI300X vs H100 vs H200 Benchmark Part 1: Training – CUDA Moat Still Alive - SemiAnalysis 链接
- oneAPI: A Viable Alternative To CUDA* Lock-in - Intel 链接
- Introducing Triton: Open-source GPU programming for neural networks - OpenAI 链接
- Welcome to Triton’s documentation! 链接
- Mojo : Powerful CPU+GPU Programming - Modular 链接
- The DOJ and Nvidia: AI Market Dominance and Antitrust Concerns - AAF 链接
- 路透社:“法国将因反垄断违规行为制裁英伟达” - 汉内雷 链接
- Key Analysis of China’s Antitrust Investigation into Nvidia - Ming-Chi Kuo 链接
- GTC 2025 精彩亮点,资讯不断 - NVIDIA Blog Korea 链接
- NVIDIA Transitions Fully Towards Open-Source GPU Kernel Modules - NVIDIA Developer Blog 链接