Would you believe that the cutting-edge technology of ChatGPT began in a casino in Monaco? Let’s trace the grand evolution of Large Language Models (LLMs).
- The probabilistic ideas that sparked artificial intelligence, the principles of the Monte Carlo method
- The dark ages of AI and the multilayer perceptron that overcame them, leading to the big bang of deep learning
- Innovations in the transformer architecture that made modern Large Language Models possible
- The future of technology heading towards agent AI beyond ChatGPT and the current status in Korea
The Dawn of Artificial Intelligence: The Emergence of Probability and Neural Networks
In the winter of 2022, the world was captivated by the AI chatbot, ChatGPT, which appeared as if by magic. This astonishing technology answered our questions seamlessly, wrote poetry, and generated code, shocking the globe. It felt as if the future from a science fiction movie had suddenly become reality.
But was all of this truly a miracle that happened overnight? Or was it the fruit of a relentless journey spanning decades that we were unaware of? To answer this question, we must travel back in time. Surprisingly, the journey began not in a cutting-edge computer lab, but from an idea inspired by chance and probability in a casino in Monaco.
1. The Secret of the Casino: The Monte Carlo Algorithm Taming Uncertainty
Why mention a casino when discussing the history of artificial intelligence? At the beginning of everything lies a unique methodology known as the ‘Monte Carlo algorithm.’ This name is derived from the famous gambling city of Monaco, and its principles are deeply related to the probability games of gambling.
The essence of the Monte Carlo method is ’to try many random samples.’ When faced with problems that are too complex or impossible to calculate mathematically, this technique obtains approximations close to the answer through countless random attempts.
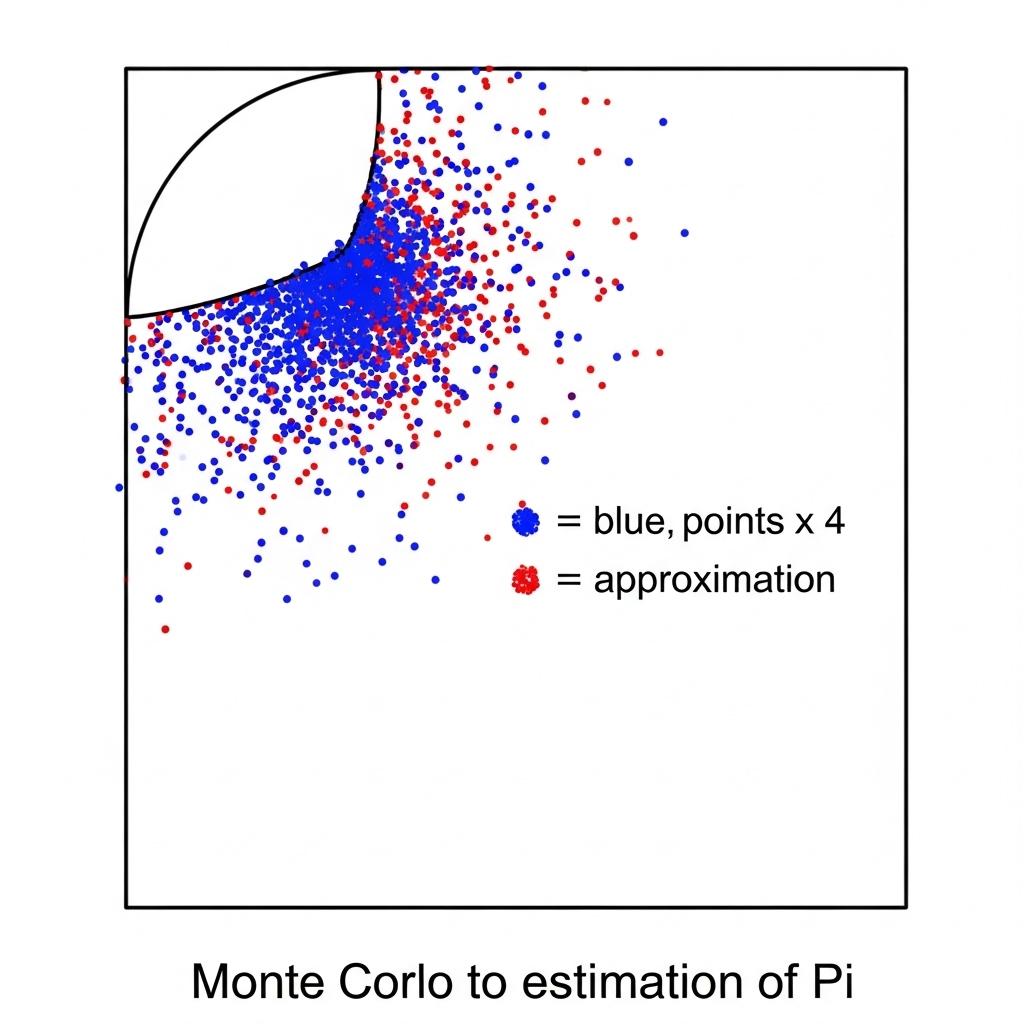
By drawing a circle that fits perfectly inside a square and randomly placing points, we can calculate an approximation of pi based on the ratio of points.
This idea was utilized in games like chess or Go, where the number of possible outcomes is nearly infinite, to randomly explore a few promising paths instead of calculating every possibility to estimate the optimal move. Later, ‘AlphaGo,’ which defeated Lee Sedol 9-dan, also used ‘Monte Carlo Tree Search (MCTS)’ as its core weapon. This approach, based on probability, aligns closely with the fundamental philosophy of Large Language Models that predict the next word probabilistically.
2. The Birth of Artificial Intelligence and the Fork in the Road
In 1956, the term ‘Artificial Intelligence (AI)’ first appeared at the Dartmouth workshop, leading AI research to split into two main directions.
- Symbolism: A top-down approach that views human intelligence as the result of logical rules and symbol manipulation, aiming to program it.
- Connectionism: A bottom-up approach inspired by the structure of the brain, believing that connecting numerous artificial neurons would lead to the emergence of intelligence.
In the connectionist camp, the ‘Perceptron’ developed by psychologist Frank Rosenblatt in 1958 was the first practical artificial neural network model that mimicked brain neurons. It had a simple structure that received multiple inputs, multiplied them by weights, and activated when the sum exceeded a certain threshold. The innovative aspect was that these weights could be ’learned’ from data.
3. The First Winter: The XOR Problem that Frustrated AI
The perceptron successfully solved ’linear separability’ problems, such as AND or OR, injecting optimism into the AI research community.
However, this optimism crumbled in the face of the very simple problem known as ‘XOR (exclusive OR).’ XOR is true only when the two input values are ‘different,’ and this outcome cannot be separated by any straight line.
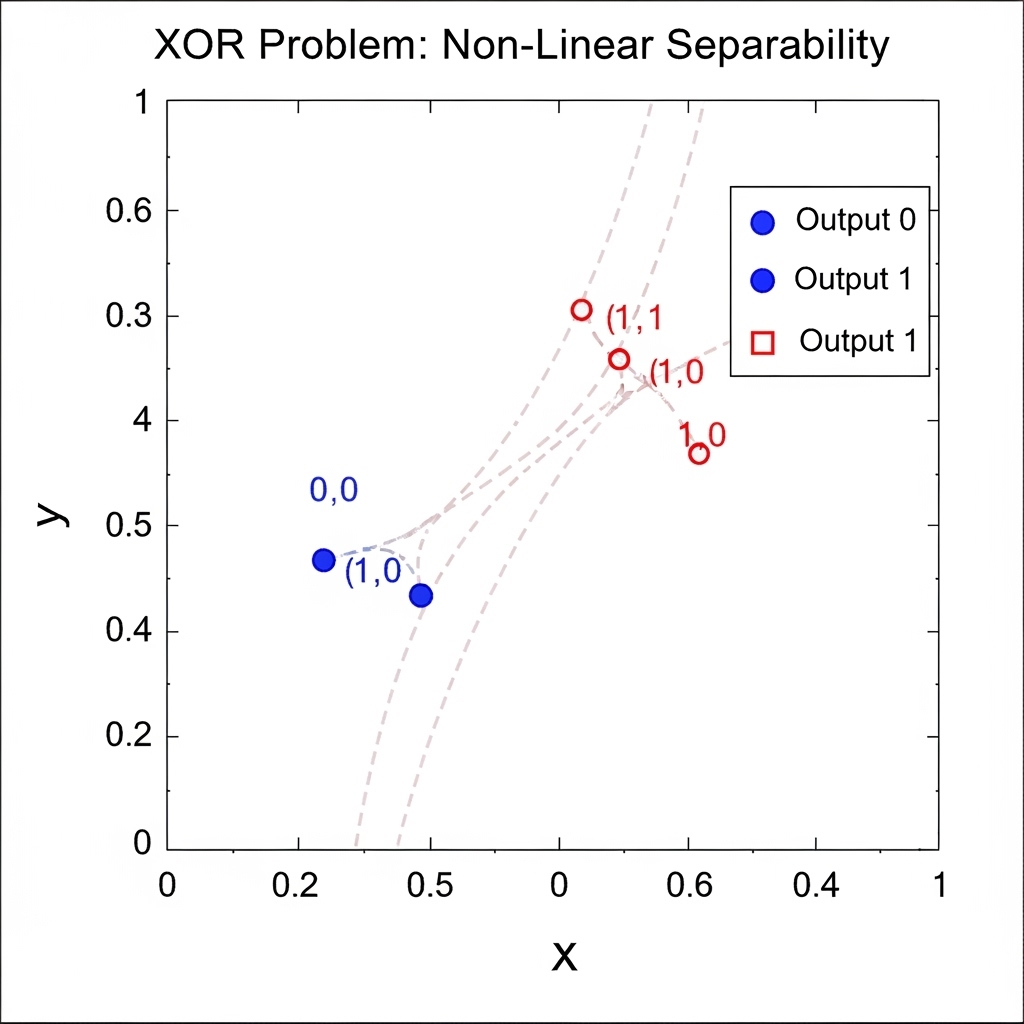
In 1969, Marvin Minsky mathematically proved this limitation, leading to a shift from hope to disappointment in AI, resulting in a sharp decline in investment known as ‘AI Winter.’ Personally, I believe the shock of the XOR problem was akin to having all the ingredients and recipes but lacking a crucial seasoning that ruined the dish. The fact that this simple problem crushed expectations for AI as a whole and ushered in a long stagnation teaches us that innovation can often be hindered not by monumental obstacles but by small details.
The Leap of Deep Learning and the Dawn of Large Language Models
After enduring a harsh winter, AI evolved into deeper and more complex structures, seizing another opportunity for a leap.
4. The Savior Ending the Dark Ages: Multi-Layer Perceptron and Backpropagation
The end of the first AI winter came with the ‘Multi-Layer Perceptron (MLP),’ which implemented the idea of “if one line doesn’t work, let’s use multiple lines.” MLP added one or more ‘hidden layers’ between the input and output layers. The hidden layers transformed data non-linearly, enabling the solution of problems like XOR that single-layer perceptrons could not solve.
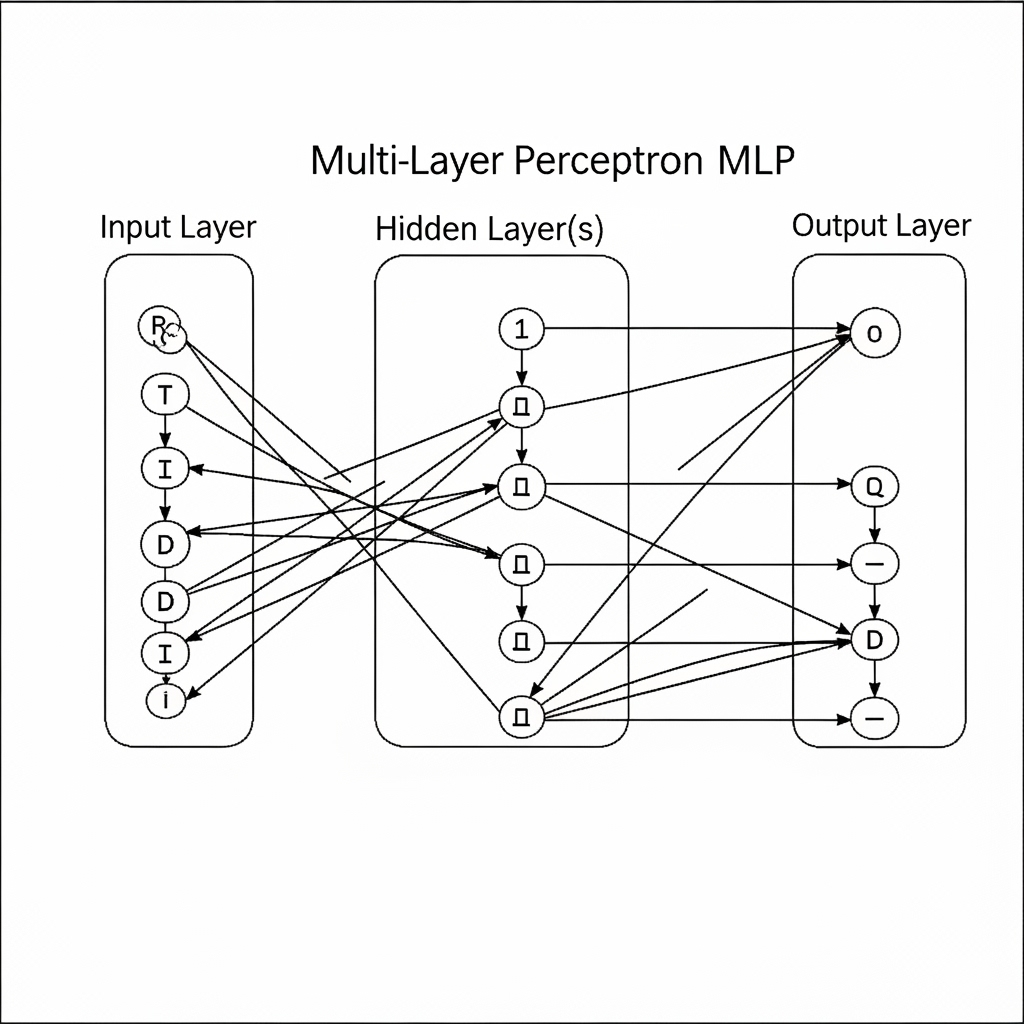
However, training this complex network posed a challenge. The solution to this problem was the ‘Backpropagation’ algorithm. Backpropagation calculates how much each connection (weight) contributed to the error by propagating the error of the final result backward, becoming a powerful tool for training deep neural networks.
5. 2012: The Big Bang of Deep Learning with the Arrival of AlexNet
While theoretical weapons were established in the 1980s, deep learning needed ‘big data’ and ‘GPUs’ to unleash its potential. The release of the 14 million image dataset ‘ImageNet’ in 2009, combined with the powerful parallel processing capabilities of GPUs, finally completed the trinity.
In 2012, Professor Geoffrey Hinton’s team won the ImageNet Challenge with a deep convolutional neural network (CNN) called ‘AlexNet,’ achieving an overwhelming error rate of 15.3% and signaling the start of the deep learning era. This event spread the belief that ‘scale equals performance,’ foreshadowing the emergence of Large Language Models.
6. Understanding the Flow of Time: Recurrent Neural Networks (RNN)
After conquering images, AI’s next goal was sequential data, where ‘order’ is crucial, like language. The model that emerged for this purpose was the ‘Recurrent Neural Network (RNN).’ RNN created a ‘recurrent’ loop within the network to remember information from previous steps and incorporate it into current calculations.
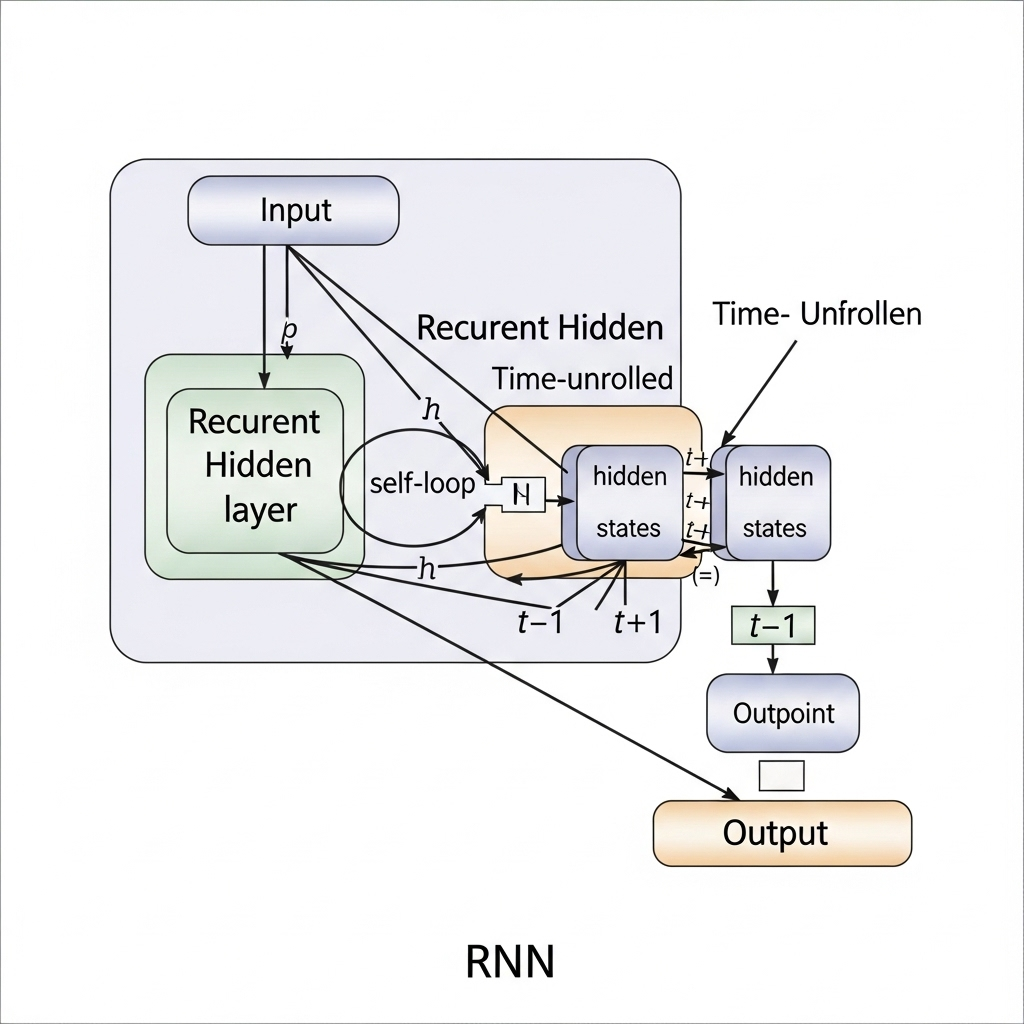
However, RNNs had a critical weakness known as the ’long-term dependency problem,’ where they tended to forget information from earlier parts of a sentence as it grew longer. Improved models like LSTM and GRU emerged, but the fundamental limitation of needing to process sequentially remained.
The Age of Giants: Transformers and Large Language Models
In 2017, a groundbreaking paper emerged, ushering in the true era of Large Language Models.
7. “Attention Is All You Need”: The Transformer that Changed the World
In 2017, Google published a paper introducing the innovative architecture known as the ‘Transformer,’ completely discarding the ‘recurrent’ structure that underpinned sequential data processing.
Transformers utilize the ‘Self-Attention’ mechanism to lay out all words at once and simultaneously calculate the importance of each word’s relationship with all other words in the sentence.
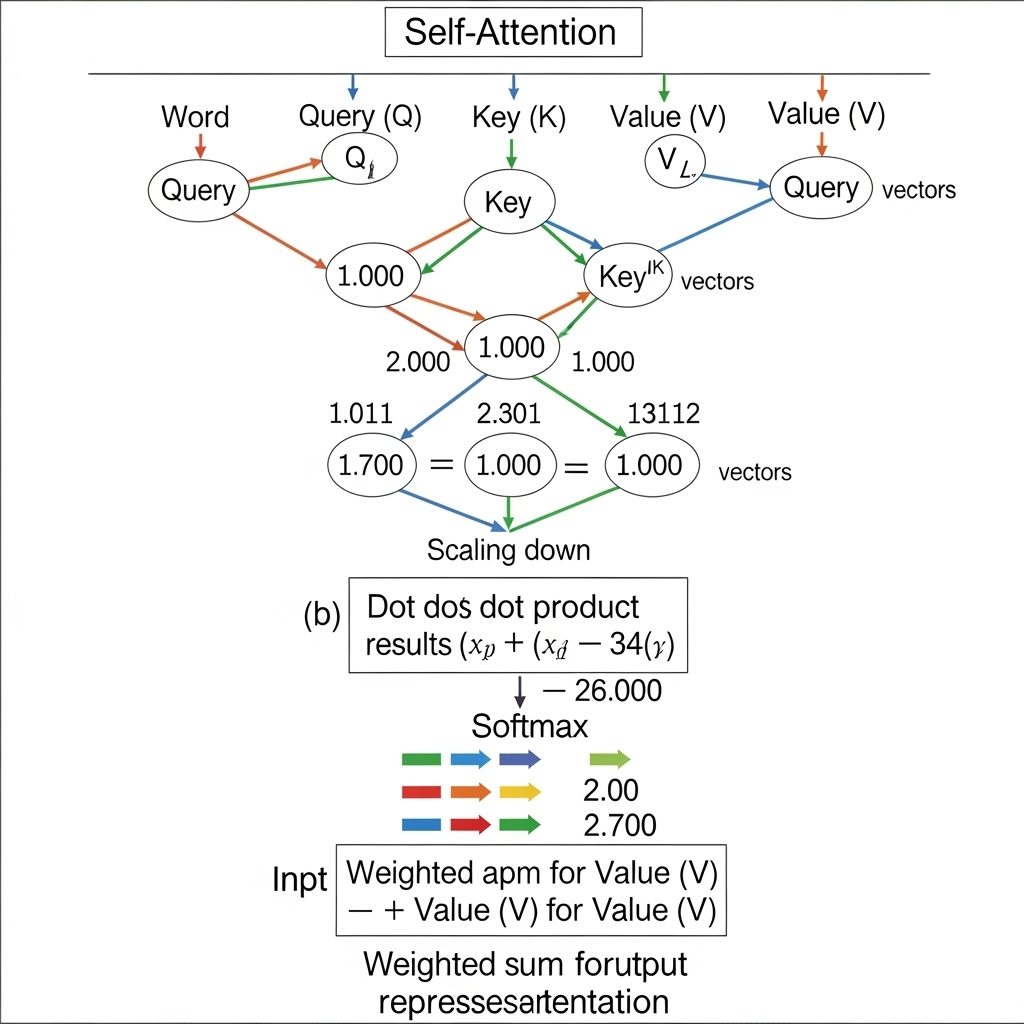
This approach fundamentally resolved the long-term dependency problem and allowed all calculations to be processed in parallel, maximizing GPU performance to its limits. This overwhelming efficiency opened the door to an era of ‘Large’ language models that were previously unimaginable.
8. The Age of Giants: BERT and GPT
Based on transformers, two giant models that divided the world of natural language processing, BERT and GPT, were born. To simplify, BERT is the detective, and GPT is the storyteller.
- BERT (The Context Detective): Trained using a ‘masked language model’ approach that examines both preceding and following contexts to fill in blanks in sentences. By considering the entire sentence bidirectionally, it excels in understanding subtle meanings of words and is utilized as a core technology in Google’s search engine.
- GPT (The Creative Storyteller): Trained to predict the most probable word following a given word. This ‘autoregressive’ method demonstrates powerful capabilities in creatively ‘generating’ new text. Notably, GPT-3 showcased ‘few-shot learning’ abilities, performing new tasks with just a few examples, opening the door to the potential of general AI.
9. The Birth of Human-like AI: The Secret of ChatGPT, RLHF
While GPT-3 was remarkable, it sometimes generated falsehoods or harmful content. A process was needed to ‘align’ the model with human intentions and values.
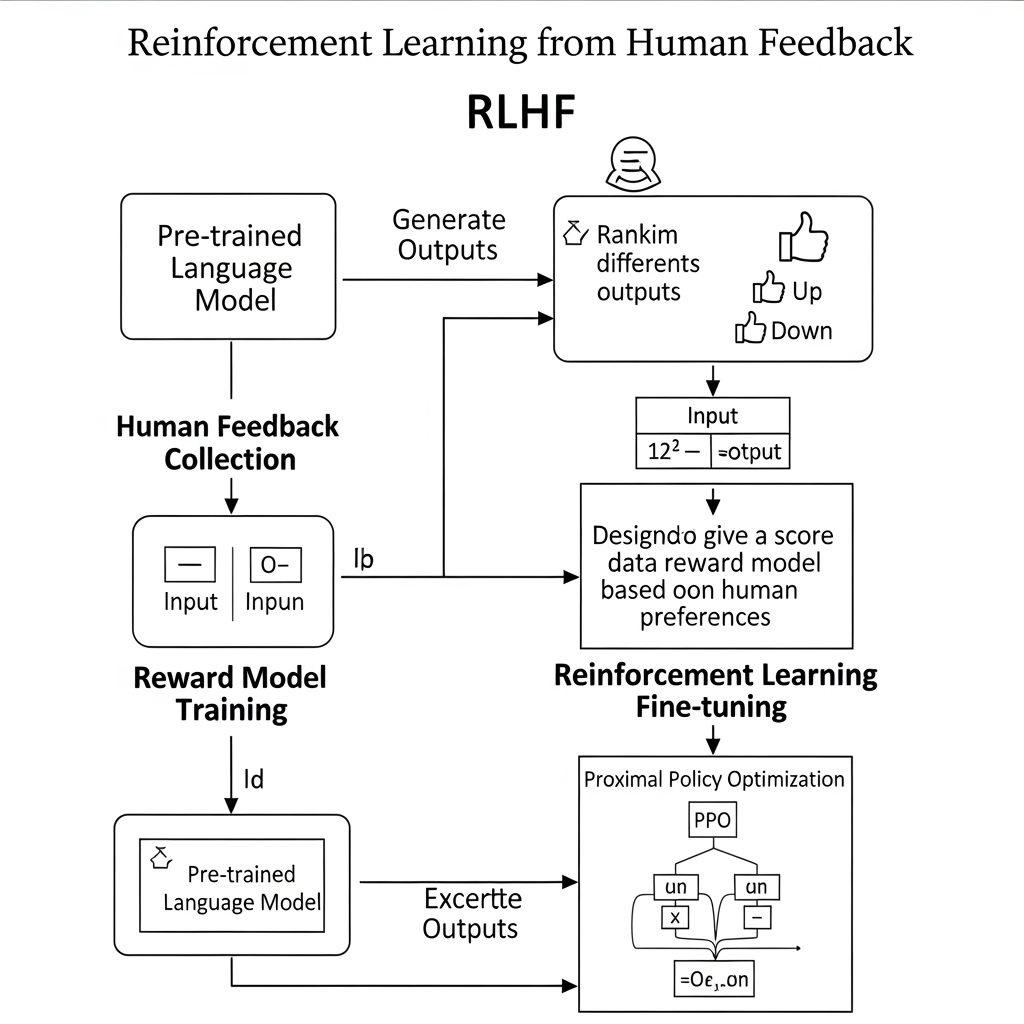
The key technology that solved this problem and gave birth to ChatGPT is ‘Reinforcement Learning from Human Feedback (RLHF).’
- Step 1 (Instruction Tuning): Teaches the model the basic ability to follow user instructions using an ‘instruction-answer’ dataset.
- Step 2 (Reward Model Training): By ranking preferences among various answers, humans train a ‘judge AI’ that scores which answers are better.
- Step 3 (Reinforcement Learning): When the Step 1 model generates answers, the Step 2 judge AI scores them, and the model adjusts itself to receive higher scores.
Recently, more efficient technologies like ‘Direct Preference Optimization (DPO)’ have also gained attention for simplifying this process.
Current Status and Future of Large Language Models in South Korea
In the LLM war triggered by ChatGPT, domestic companies are fiercely competing to secure ‘Sovereign AI’ that deeply understands Korean language and culture.
Comparison of Representative LLMs in South Korea
| Developer | Model Name | Key Features |
|---|---|---|
| Naver | HyperCLOVA X | Based on vast Naver data, specialized in Korean, ‘Thinking’ feature, integration with its own services (search, shopping, etc.) |
| Kakao | Koala (formerly KoGPT) | Open-source (commercial use possible), lightweight and efficient, excellent performance in Korean, multimodal support |
| SKT | A.X (A-dot-X) | Developed ‘from scratch,’ multimodal (VLM), high-performance document encoder, telecom specialization |
| LG AI Research | EXAONE | Expert AI, hybrid of reasoning and generation, specialized in fields like math/coding/science |
| Upstage | SOLAR | Lightweight model (SLM) with top-level performance, high efficiency and cost-effectiveness, ranked first on global leaderboards |
In this intensifying competition, the ‘Open Ko-LLM Leaderboard’ led by Upstage serves as a standard benchmark for objectively comparing the performance of domestic models, contributing to the development of the domestic AI ecosystem.
Conclusion: The Journey Towards Agent AI and Our Challenges
The journey of AI, which began with rolling dice, has opened the era of Large Language Models that converse like humans after over 70 years. Now, technology is moving towards the next stage of ‘Agentic AI.’ Agent AI is an active problem solver capable of setting goals, planning, and autonomously performing complex tasks using tools.
In the face of this dazzling future, Geoffrey Hinton warns of the dangers of superintelligence, while Yann LeCun points out the current LLMs’ lack of ‘common sense’ and advocates for the need for new architectures. Their debate shows that we are not at the pinnacle of technology but at a new starting point.
Key Takeaways
- A Journey Starting from Probability: AI began with a probabilistic approach inspired by the probability games of casinos, seeking the ‘most plausible answer’ rather than perfect calculations.
- The Revolution of Transformers: The transformer architecture overcame the limitations of sequential processing, maximizing parallel processing and contextual understanding, ushering in the era of Large Language Models (LLMs).
- Alignment with Humans and the Future: ChatGPT was aligned with human intentions through RLHF, and AI is now on the verge of evolving into ‘Agentic AI’ that plans and executes autonomously.
The next chapter, deciding how to develop this powerful new technology and integrate it responsibly into society, lies in all of our hands. How about experiencing the possibilities and limitations of one of the domestic LLMs introduced today?
References
- Monte Carlo Method - Namu Wiki link
- Dartmouth Conference - Wikipedia link
- AI Winter - Wikipedia link
- What is Backpropagation? - IBM link
- ImageNet - Wikipedia link
- What is Recurrent Neural Network (RNN)? - AWS link
- [1706.03762] Attention Is All You Need - arXiv link
- The Illustrated Transformer - Jay Alammar link
- Illustrating Reinforcement Learning from Human Feedback (RLHF) - Hugging Face link
- Current Status and Comparison of Domestic LLM Models - MSAP.ai link