相信吗?ChatGPT,这个先进技术的象征,它的起源竟然是一个在摩纳哥赌场的想法。让我们一起追溯大型语言模型(LLM)的宏大演变史。
- 人工智能的开端:蒙特卡洛方法的概率思想
- 人工智能的“寒冬”与多层感知机、深度学习的爆发
- 催生现代大型语言模型的Transformer架构的革命
- 从ChatGPT走向Agent AI的技术未来与中国现状
人工智能的黎明:概率与神经网络的出现
2022年的冬天,世界为人工智能聊天机器人ChatGPT的出现而疯狂。这项技术仿佛一夜之间出现,能流畅地回答我们的问题,写诗,写代码,震惊了全世界。这就像科幻电影中的未来突然变成了现实。
但这一切真的是一夜之间的奇迹吗?还是经过了几十年我们不知道的艰辛努力才取得的成果?为了回答这个问题,我们需要回到过去。令人惊讶的是,这段旅程的起点并不是最先进的计算机实验室,而是源于一个在摩纳哥赌场获得的灵感,那里充满了偶然和概率。
1. 赌场的秘密:驾驭不确定性的蒙特卡洛算法
为什么在谈论人工智能历史时要提到赌场?一切的开端都源于一种叫做“蒙特卡洛算法”的独特方法。这个名字来自摩纳哥著名的赌博城市蒙特卡洛,它的原理也与赌博的概率游戏有着密切的关系。
蒙特卡洛方法的核心是**“反复进行大量随机尝试”**。 当遇到在数学上计算过于复杂或不可能解决的问题时,通过无数次随机尝试来获得接近答案的近似值。
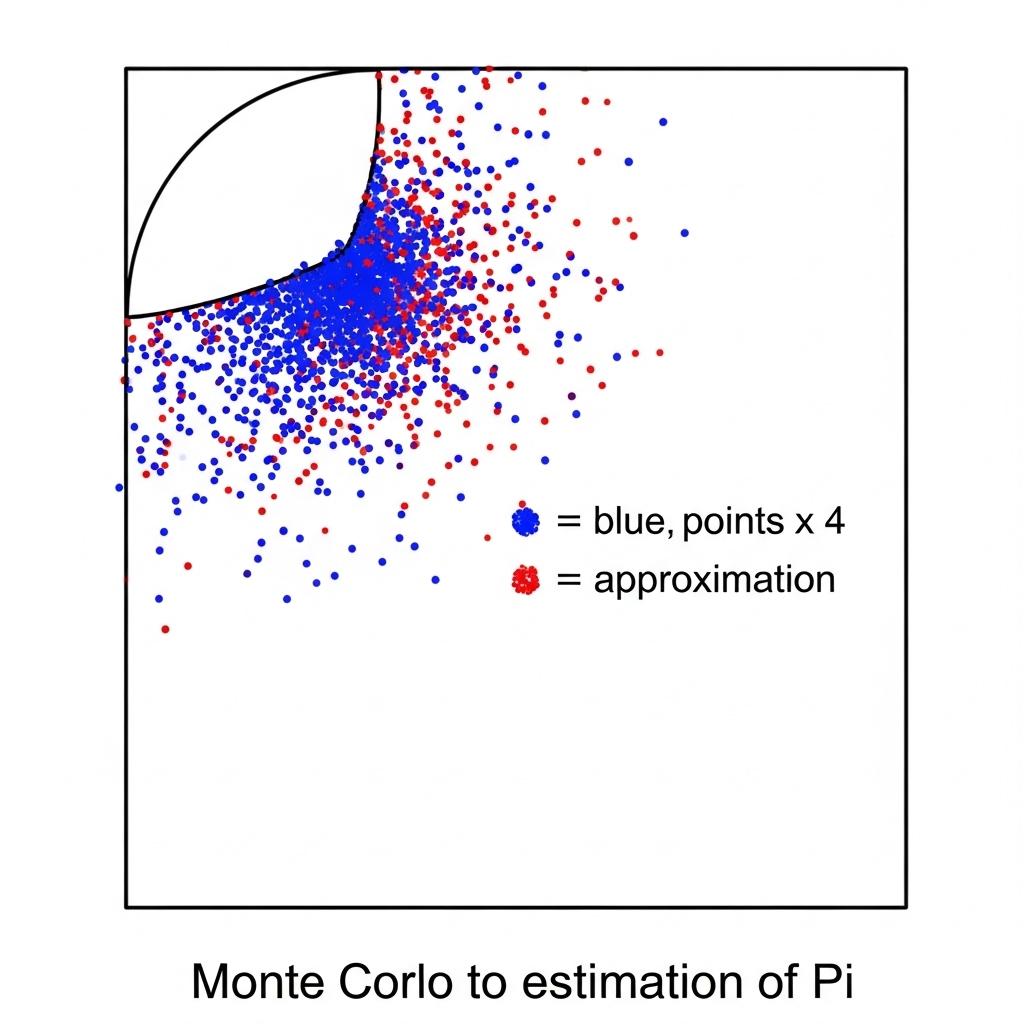
在一个与正方形内切的圆内随机打点,通过点的数量比例可以计算出圆周率的近似值。
这个想法被用于国际象棋或围棋等组合爆炸的游戏中,不是计算所有可能的局面,而是通过随机探索一些有希望的路径来估计最佳着法。后来击败李世石九段的“AlphaGo”,也使用了“蒙特卡洛树搜索(MCTS)”这一思想作为其核心武器。这种基于概率寻找最可能答案的方法,与后来预测下一个词的大型语言模型的基本理念不谋而合。
2. 人工智能的诞生与两条道路
1956年,在达特茅斯会议上,“人工智能(Artificial Intelligence)”这个词首次出现,AI研究大致分为两个方向:
- 符号主义(Symbolism): 将人类智能视为逻辑规则和符号操作的结果,并试图对其进行编程,这是一种自上而下的方法。
- 连接主义(Connectionism): 从大脑结构中获得灵感,相信连接大量人工神经元就能涌现出智能,这是一种自下而上的方法。
在连接主义阵营中,1958年心理学家弗兰克·罗森布拉特开发的**“感知机(Perceptron)”**是第一个模仿大脑神经元并具有实用性的人工神经网络模型。它结构简单,接收多个输入,进行加权求和,当总和超过某个阈值时就激活。其创新之处在于,这些权重可以从数据中“学习”。
3. 第一次寒冬:XOR问题让AI受挫
感知机成功解决了AND或OR等可以用一条直线将正例和负例分开的“线性可分”问题,给AI研究界带来了乐观情绪。
但这种乐观情绪在“XOR(异或)”这个非常简单的问题面前破灭了。XOR只有在两个输入值“不同”时才为真,而这个结果无法用任何一条直线来划分。
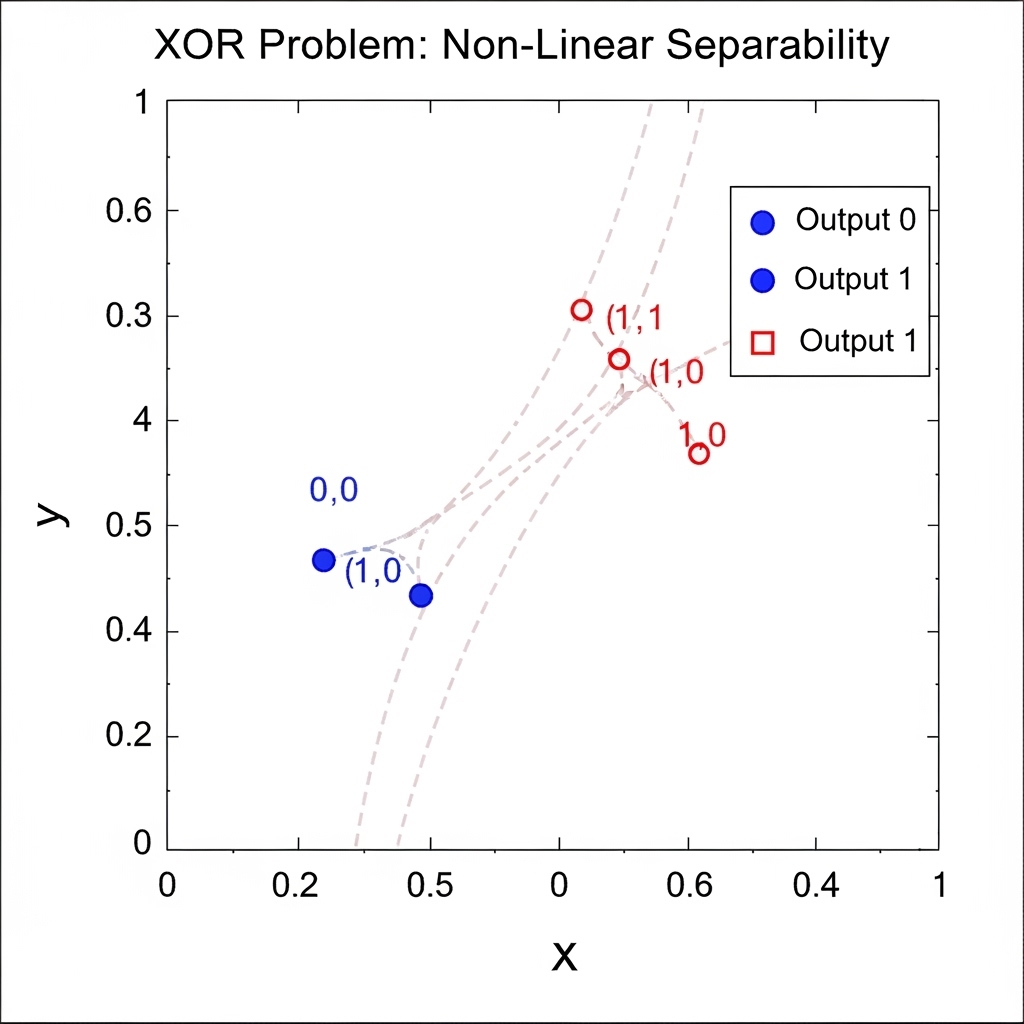
1969年,马文·明斯基在数学上证明了这一局限性后,人们对AI的期望变成了失望,投资急剧下降,迎来了“AI寒冬(AI Winter)”。我个人认为XOR问题带来的打击,就像拥有了所有食材和食谱,却因为缺少一种关键调味料而毁了这道菜。这个简单的问题竟然让人们对整个AI的期望破灭,并带来了漫长的低迷期,这给我们上了一课:创新往往不是被巨大的困难绊倒,而是可能栽在微小的细节上。
深度学习的飞跃与大型语言模型的序幕
经历了严酷的冬天,AI以更深、更复杂的结构进化,再次迎来了飞跃的机会。
4. 结束黑暗时期的救星:多层感知机与反向传播
结束第一个AI寒冬的是“当一层不够时,就用多层”的理念实现的“多层感知机(Multi-Layer Perceptron, MLP)”。MLP在输入层和输出层之间增加了一个或多个“隐藏层(hidden layer)”。隐藏层可以对数据进行非线性转换,从而解决单层感知机无法解决的XOR等问题。
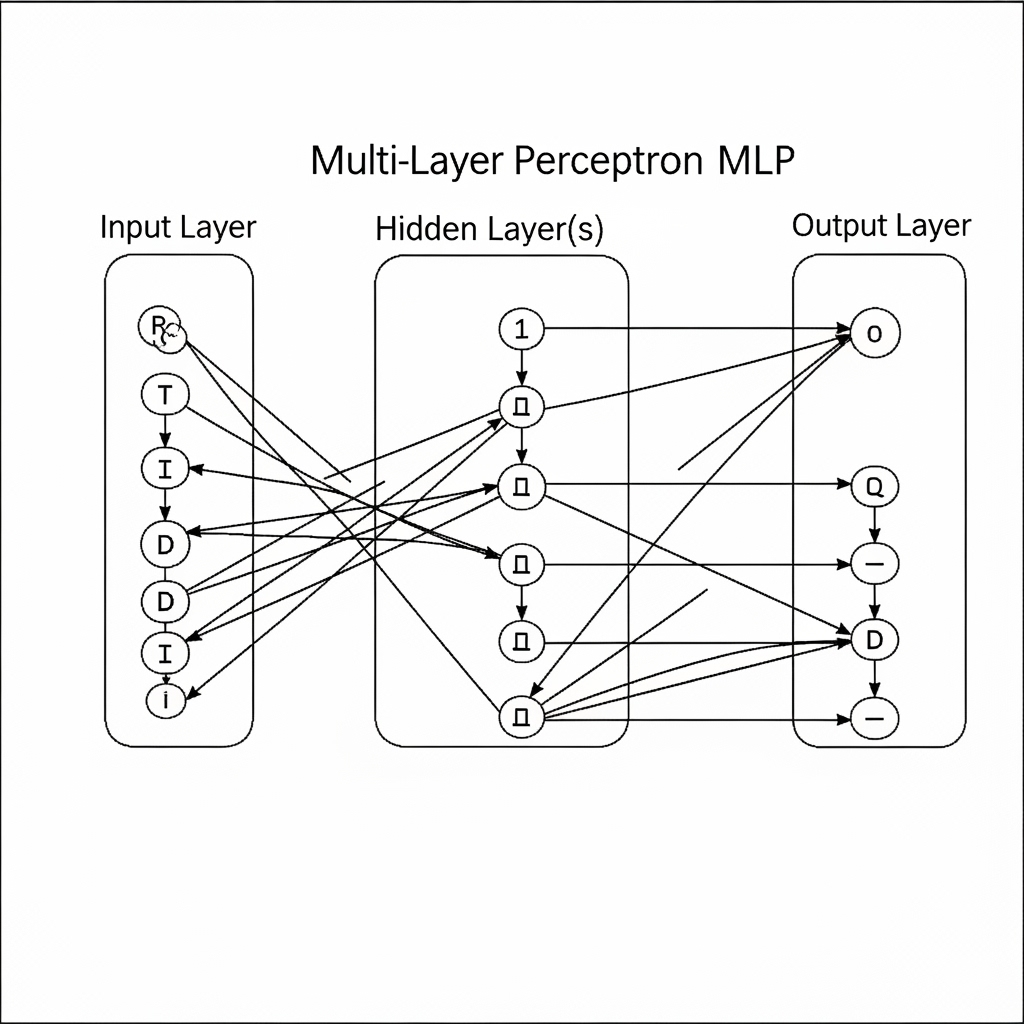
但是,训练这些复杂的网络却是个问题。解决了这个难题的是**“误差反向传播(Backpropagation)”**算法。反向传播将最终结果的误差反向传播,计算每个连接(权重)对误差的贡献并进行修正,这成为了训练深度神经网络的强大武器。
5. 2012年,深度学习的爆发:AlexNet的出现
1980年代,理论武器已经准备就绪,但要让深度学习爆发出全部潜力,还需要**“大数据”和“GPU”。2009年发布的包含1400万张图像的“ImageNet”**数据集,以及GPU强大的并行计算能力结合在一起,终于实现了“三位一体”。
2012年,杰弗里·辛顿教授团队的深度卷积神经网络(CNN)“AlexNet”以15.3%的惊人错误率赢得了ImageNet挑战赛,标志着深度学习时代的到来。这一事件 확산了“规模即性能”的信念,预示了后来大型语言模型的出现。
6. 理解时间的流逝:循环神经网络(RNN)
征服图像之后,AI的下一个目标是像语言一样“顺序”很重要的**“序列数据(Sequential Data)”。为此,模型“循环神经网络(Recurrent Neural Network, RNN)”**应运而生。RNN通过在网络内部创建“循环”来记忆前一阶段的信息并将其用于当前的计算。
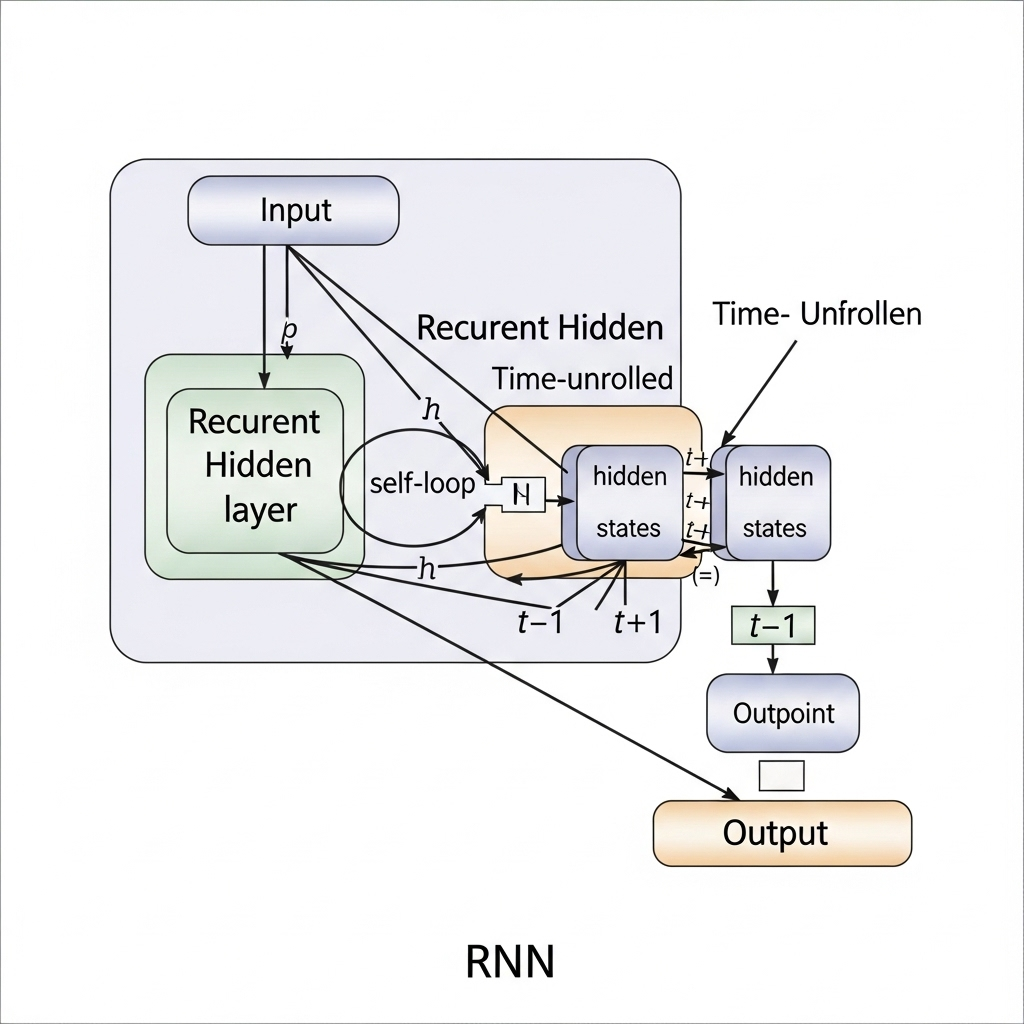
然而,RNN存在一个致命的缺点,即随着句子变长,它会忘记前面的信息,这就是**“长期依赖问题”。虽然LSTM和GRU**等改进模型出现了,但需要顺序处理的根本性限制仍然存在。
当今的“神”:Transformer与大型语言模型
2017年,一篇改变一切的论文发表,真正开启了大型语言模型的时代。
7. “Attention Is All You Need”:改变世界的Transformer
2017年,谷歌发表的一篇论文介绍了革命性的**“Transformer(Transformer)”**架构,彻底抛弃了曾是序列数据处理基础的“循环”结构。
Transformer通过**“自注意力(Self-Attention)”**机制,一次性展开所有单词,并同时计算每个单词与句子中所有其他单词之间关系的权重。
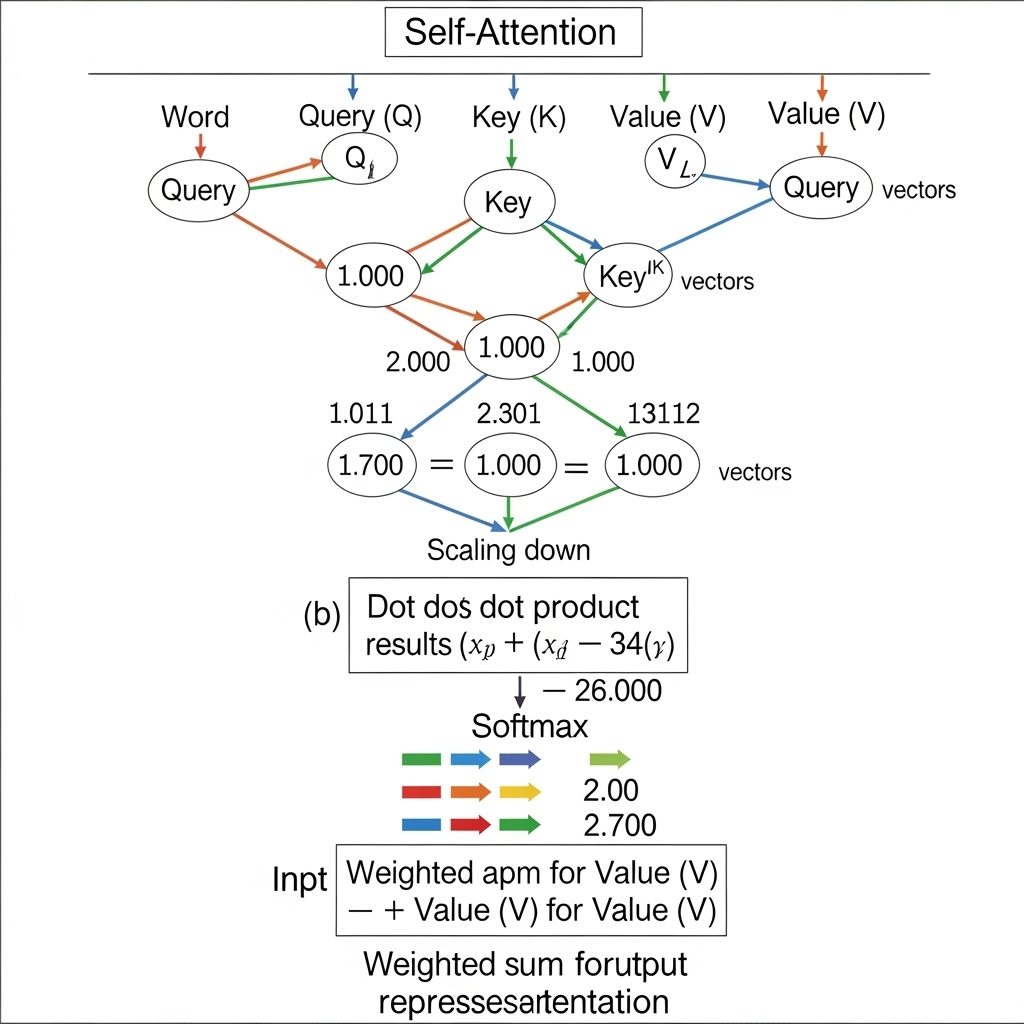
这种方式不仅从根本上解决了长期依赖问题,而且由于所有计算都可以并行处理,充分发挥了GPU的性能。这种压倒性的效率开启了一个此前无法想象的**“大型(Large)”**语言模型的时代。
8. 巨头时代:BERT与GPT
基于Transformer,自然语言处理领域出现了两个巨头模型:BERT和GPT。简单来说,BERT是侦探,GPT是说书人。
- BERT(语境侦探): 以**“掩码语言模型”**的方式进行训练,通过查看句子前后文来填充被掩盖的词语。由于它从双向考虑整个句子,因此在理解单词的细微含义方面具有卓越的“理解”能力,并被用作Google搜索引擎的核心技术。
- GPT(创意说书人): 以预测给定单词后最有可能出现的单词的方式进行训练。这种“自回归”方式使其在创造性地“生成”新文本方面具有强大能力。特别是GPT-3通过少量示例就能执行新任务的**“少样本学习(Few-shot learning)”**能力,为通用人工智能的潜力打开了大门。
9. 诞生“人性化”AI:ChatGPT的秘密,RLHF
GPT-3虽然令人惊叹,但有时也会产生虚假或有害的内容。模型需要进行“对齐(Alignment)”的过程,使其符合人类的意图和价值观。
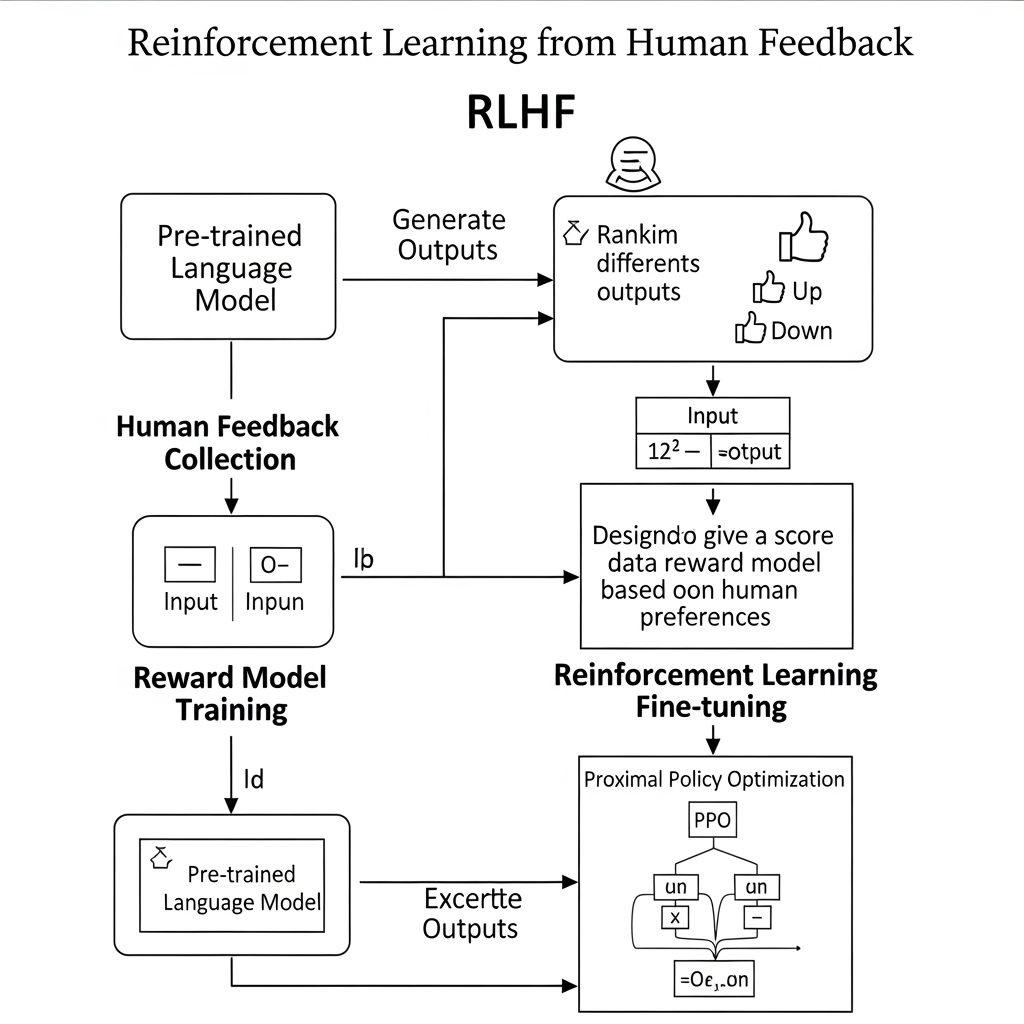
解决了这个问题的、催生ChatGPT的核心技术就是**“通过人类反馈强化学习(RLHF)”**。
- 第一阶段(指令微调): 使用“指令-示范回答”数据集,教会模型遵循用户指令的基本能力。
- 第二阶段(奖励模型训练): 人类对多个回答进行偏好排序,训练出能够评估回答好坏并打分的“裁判AI”。
- 第三阶段(强化学习): 第一阶段的模型生成回答,第二阶段的裁判AI进行评分,模型会自我修正以获得更高的分数。
最近,**“直接偏好优化(DPO)”**等更高效的技术也因简化了这一过程而受到关注。
中国大型语言模型的现状与未来
在ChatGPT引发的LLM大战中,中国企业也在激烈竞争,力求掌握理解中文和中国文化的“主权AI”。
这里是韩国大型语言模型(LLM)的比较。
| 开发者 | 模型名称 | 主要特点 |
|---|---|---|
| Naver | HyperCLOVA X | 基于庞大的Naver数据,专门针对韩语优化,“Thinking”功能,与自家服务(搜索、购物等)集成 |
| Kakao | Koala (原KoGPT) | 开源(可商用),轻量化和高效,韩语性能优异,支持多模态 |
| SKT | A.X (A Dot X) | “From Scratch”自主开发,多模态(VLM),高性能文档编码器,通信领域专用 |
| LG AI Research | EXAONE | 专家级AI,推理+生成混合模式,专注于数学/编程/科学等专业领域 |
| Upstage | SOLAR | 轻量级模型(SLM)但性能顶尖,效率高,成本效益好,全球排行榜第一 |
在竞争日益激烈的背景下,由Upstage主导的“Open Ko-LLM Leaderboard”成为客观比较国内模型性能的标准基准,为韩国AI生态系统的发展做出了贡献。
结论:通往Agent AI的旅程与我们的任务
AI的旅程始于一次掷骰子,经过70多年,已经迎来了像人类一样对话的大型语言模型(LLM)时代。现在,技术正迈向下一个阶段——“Agentic AI”。Agentic AI是主动的问题解决者,它们能自主设定目标、制定计划,并利用工具来完成复杂的任务。
在这个令人瞩目的未来面前,Geoffrey Hinton警告了超智能的危险,而Yann LeCun则指出当前LLM缺乏“常识”,并主张需要新的架构。他们的争论表明,我们正处于一个新的起点,而非技术的顶峰。
核心要点
- 始于概率的旅程: AI并非始于完美的计算,而是源于从赌场概率游戏中获得的灵感,即寻找“最可能的答案”的概率方法。
- Transformer的革命: Transformer架构克服了顺序处理的局限,最大化了并行处理和上下文理解能力,开启了大型语言模型(LLM)时代。
- 与人类对齐,及未来: ChatGPT通过RLHF(人类反馈强化学习)与人类意图对齐,现在AI正朝着能够自主规划和执行的“Agentic AI”进化。
接下来如何开发这项强大的新技术,并负责任地将其融入社会,这取决于我们所有人。为了感受这项惊人技术发展对我们的意义,为何不亲自尝试使用我们今天介绍的其中一个韩国LLM,体验它的潜力和局限性呢?
参考资料
- 蒙特卡洛方法 - Namu Wiki 链接
- 达特茅斯会议 - Wikipedia 链接
- AI寒冬 - Wikipedia 链接
- 什么是反向传播? - IBM 链接
- ImageNet - Wikipedia 链接
- 什么是循环神经网络(RNN)? - AWS 链接
- [1706.03762] Attention Is All You Need - arXiv 链接
- The Illustrated Transformer - Jay Alammar 链接
- Illustrating Reinforcement Learning from Human Feedback (RLHF) - Hugging Face 链接
- 国内LLM模型现状及比较 - MSAP.ai 链接