History often pivots on seemingly trivial, even insignificant, constraints.
If you were asked about the decisive moment that led Nvidia (NVIDIA), a company now vying for the top spot in global market capitalization in 2025, to its current glory, what would you say?
Many might recall the latest chips like the H100 or the emergence of ChatGPT.
But the starting point was far humbler, a dramatic moment in time.
It was the year 2012, and a small projectile launched by just two ‘GTX 580’ graphics cards, commonly found even in Seoul’s Yongsan Electronics Market, set everything in motion.

This article tells the story of AlexNet, which ignited the **“Big Bang of Deep Learning”** by solving problems that trillions of dollars in supercomputing power couldn’t, using cost-effective hardware. It’s also a record of Nvidia’s great symbiosis, seizing that spark and fanning it into a blaze that engulfed the entire forest.
1. Prologue: 6 Days of Revolution in Florence, 2012
September 30, 2012, at a workshop of the European Conference on Computer Vision (ECCV) held in Florence, Italy. The air in the room felt different.
At the time, the AI academic community was trapped in the ‘AI Winter’ that had lasted for decades.
Computers struggled even with the basic task of identifying a cat in a photo as a ‘cat’.
Competitors in the ImageNet competition were frustrated by the insurmountable wall of a 26% error rate.
Then, Professor Geoffrey Hinton’s team (SuperVision) from the University of Toronto presented their results, which were nothing short of shocking.
15.3% error rate.
An overwhelming figure that shattered the previous record by over 10 percentage points.
What was even more astonishing was the equipment they used.
Instead of the university’s supercomputers, which cost tens of billions of won, these results were achieved by running _two consumer-grade GPUs (GTX 580) for just 6 days._
This moment would later be dubbed the “Big Bang of AI” by Jensen Huang.

2. The Dark Ages: Supercomputers That Couldn’t Recognize a ‘Cat’
Let’s rewind the clock to before 2012.
At the time, computer vision technology was dominated by ‘Hand-crafted Features’, relying on human intuition.
“Cats have pointy ears.”
“Eyes are oval-shaped.”
“They have whiskers.”
Researchers diligently tried to define these rules mathematically (using SIFT, HOG, etc.). But reality was harsh.
A crouching cat, a cat seen only from behind, a cat hidden in the shadows… Facing variables not pre-programmed by humans, the algorithms were helpless.
Experts called this the insurmountable chasm between data represented as 0s and 1s and actual concepts, the ‘Semantic Gap’.
Even Google, using 16,000 CPU cores, conducted an experiment to find cat faces, but the cost-effectiveness was dismal.
Nvidia was equally frustrated.
In 2006, they ambitiously launched the CUDA platform, allowing GPUs to be used for general-purpose computation, but there was no ‘killer app’ to utilize it effectively.
The market treated them merely as a ‘company for gaming parts’.
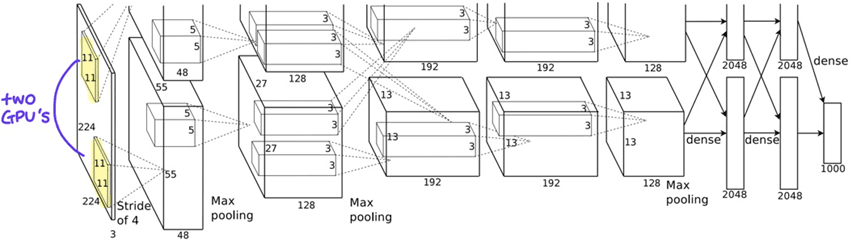
3. Genius Born from Scarcity: Surpassing the 3GB Memory Limit
Alex Krizhevsky, the lead author of AlexNet, intuitively felt that Deep Neural Networks held the answer.
The problem was computational load. The only tools available to the impoverished graduate student were two discarded GTX 580s from the lab.
This led to a historic ‘scarcity’. The VRAM of a GTX 580 was a mere 3GB.
It was woefully insufficient to hold a massive neural network with 60 million parameters and 650,000 neurons.
Most people would have given up, saying, “The equipment isn’t good enough.” But they transformed this limitation into engineering genius.
**“Let’s split the brain in two.”
They cut the neural network in half and distributed it across two GPUs.
This became the origin of **Grouped Convolutions** and **Model Parallelism**.
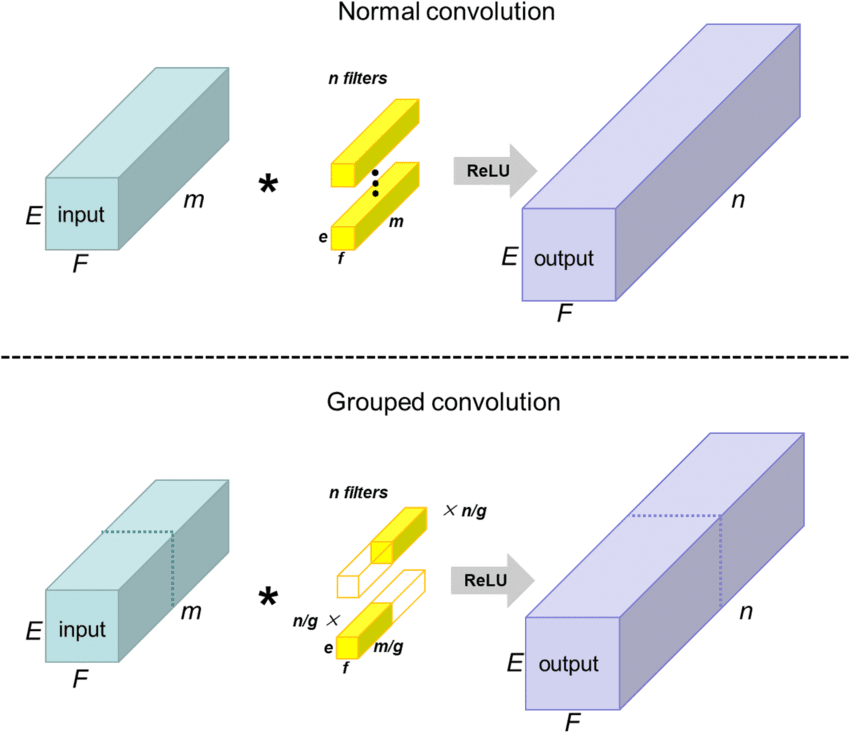
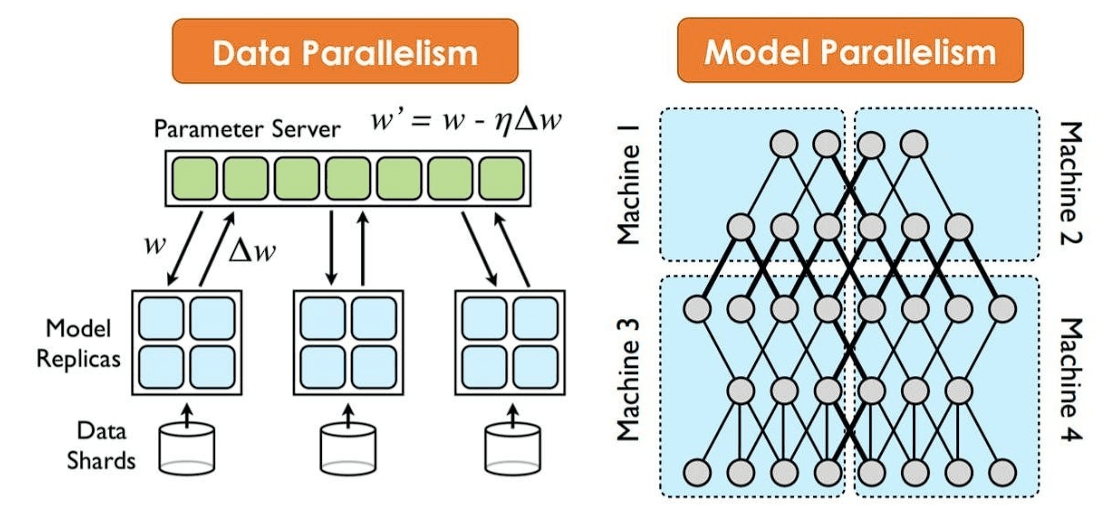
Maximizing Parallel Processing: Each GPU computed independently, exchanging data only at layers where communication was essential, thus minimizing communication bottlenecks.
Accelerated Feedback: Training that would have taken months on a CPU was reduced to 6 days, allowing for rapid iteration of experiments and failures.
Introduction of ReLU: Instead of complex functions, they adopted the deceptively simple ReLU function, $f(x)=max(0,x)$, which further accelerated training by sixfold.
Ironically, this ’trick’ to overcome the hardware limitation of ‘insufficient memory’ ultimately defined the standards for modern AI architectures.
!(https://nvidianews.nvidia.com/flickr/images/72157714138767988/original.jpg ‘CEO Jensen Huang announcing the roadmap for the AI era’)
{kind=link}
4. Jensen Huang’s Gamble: “Bet the Company”

Upon seeing the success of AlexNet, Nvidia CEO Jensen Huang was electrified.
He instinctively understood:
“The software of the future will not be coded by humans, but by data.”
In 2013, he made the decision to pour all of Nvidia’s resources into AI.
Internally, this was known as “Bet the Company.”
At the time, diverting profits from the booming gaming industry into the uncertain black hole of AI seemed like a crazy gamble.
But he remained steadfast, driving three key changes:
Redefining Hardware: The GPU architecture was completely overhauled from focusing on graphics rendering (drawing) to matrix operations (computation).
Ecosystem Building (Moat): They released the cuDNN library, enabling researchers to perform deep learning without deep hardware knowledge. This became a powerful moat, ensuring that TensorFlow and PyTorch ran primarily on Nvidia hardware.
Evolution into a Systems Company: In 2016, they built the world’s first AI supercomputer, the DGX-1, and delivered it directly to OpenAI. This was a declaration that Nvidia would become an ‘AI infrastructure company’, not just a component supplier.
5. Co-evolution: Software Sculpting Hardware
The decade since AlexNet has been a perfect pas de deux between software and hardware.
This is known as ‘Software-Defined Hardware’.
As AI models evolved, the chips evolved in tandem.
Pascal (2016): To eliminate the communication bottlenecks experienced with AlexNet, they created NVLink, an ultra-high-speed interconnect. Now, 8 GPUs operate as if they were a single, massive chip.
Volta (2017): They embedded ‘Tensor Cores’ directly into the chips, designed to intensely process matrix multiplications, the core of deep learning.
Hopper (2022) & Blackwell (2024): For Transformers and LLMs, they introduced support for 8-bit (FP8) and 4-bit (FP4) computations, drastically increasing memory bandwidth.
What struggled with 3GB of memory 12 years ago has now evolved into monstrous machines (like the B200) equipped with 192GB of HBM3e memory, capable of ingesting trillions of parameters.
6. From Gamer’s Toy to ‘AI Factory’
This technological advancement has fundamentally reshaped the economic landscape.
Nvidia, valued at 8 trillion won in 2012, became a $4 trillion (approximately 5,500 trillion won) company by 2025.
Even more remarkable is the shift in revenue structure.
In the past, Nvidia’s cash flow came from PC bangs and gamers.
Now, over 80% of its revenue originates from data centers.
Companies like Amazon, Google, and Microsoft are lining up to purchase Nvidia GPUs.
In Jensen Huang’s words, data centers are no longer just warehouses for storing data; they have become “AI Factories” that burn data to produce a new commodity: ‘Intelligence’.
In this process, SK Hynix and Samsung Electronics have also become essential partners in this vast ecosystem by supplying high-performance fuel in the form of HBM (High Bandwidth Memory).
7. Next Wave: The Revival of the Dormant Physics Engine and ‘Physical AI’
Nvidia is now preparing a new frontier, moving beyond the era of ‘perception’ opened by AlexNet and the era of ‘generation’ ushered in by ChatGPT.
This frontier is ‘Physical AI’ and Robotics.
Here, a truly fascinating technological recycling is taking place.
Do you remember ‘PhysX’ if you’re a fan of older games?
It was a physics engine acquired by Nvidia in 2008, responsible for making walls crumble and capes flutter in games.
For a while, it was considered a mere add-on feature for “making graphics prettier.”
But with the advent of the AI era, this technology has made a spectacular comeback.
When robots are trained in the real world, they tend to fall and break. _Therefore, training must occur in virtual space (Sim-to-Real), which necessitates a simulator that can perfectly calculate gravity, friction, and collisions._
Nvidia’s robotics platform, ‘Isaac’, leverages technology from its old gaming physics engine to train millions of robots simultaneously in a virtual world.

Technology that delighted gamers 20 years ago is now becoming the core infrastructure for building the cerebellum of humanoid robots.
8. Epilogue: From Perception to Embodied Intelligence
Let’s summarize.
AlexNet (2012): Gave computers **’eyes (Vision)’**.
ChatGPT (2022): Gave computers **‘mouths (Language)’**.
Next NVIDIA: Now aims to give computers **‘bodies (Body)’**.
This journey from training to inference, from virtual intelligence to physical intelligence, has always been at the center of the intense symbiosis between hardware and software.
What if the GTX 580 had sufficient memory back then?
Perhaps the revolutionary idea of ‘parallel processing’ might never have emerged.
While innovation sometimes arises from abundance, it is often born from “desperate attempts to overcome scarcity.”
We are now standing in the midst of a $4 trillion fireworks display created by that scarcity.
Where will the next spark fly from? It might be hidden within someone else’s ‘scarcity’.
References
- ImageNet Classification with Deep Convolutional Neural Networks \[AlexNet Paper\]
2. NVIDIA: The Complete History and Strategy
\[Acquired Podcast\]3. Jensen Huang on the future of physical AI and robotics
\[The Economist\]4. The Intelligent Industrial Revolution: How AI Transforms Manufacturing
\[NVIDIA Blog\]