历史的车轮,常常在那些微不足道,甚至看似无关紧要的限制条件下,转向了宏伟的方向。
如果你被问及,是什么决定性地促成了如今全球市值第一的科技巨头——英伟达(NVIDIA)——的辉煌成就,你会给出怎样的答案?
或许有人会想到最新的H100芯片,或是ChatGPT的横空出世。
然而,这一切的起点,却显得更为朴素,且发生在了一个极为戏剧性的时刻。
那就是2012年,一块在龙山电子市场随处可见的“GTX 580”显卡,仅仅两张,便点燃了后续一切的导火索。

本文讲述的是AlexNet的故事——它如何用“高性价比”的设备解决了数万亿超算都束手无策的难题,引爆了**“深度学习的大爆炸(The Big Bang of Deep Learning)”**;同时,也是英伟达如何抓住这火种,将其燎原成熊熊大火的伟大共生记录。
1. 序幕:2012年的佛罗伦萨,6天的革命
2012年9月30日,在意大利佛罗伦萨举行的计算机视觉国际会议(ECCV)的一个研讨会上。空气中弥漫着与往日不同的气息。
彼时,人工智能学界仍深陷在长达数十年的“AI寒冬(AI Winter)”之中。
计算机就连识别一张猫的照片并称之为“猫”都显得十分困难。
在ImageNet图像识别竞赛中,参赛者们正被26%的错误率这道难以逾越的鸿沟所困扰。
这时,来自多伦多大学的**杰弗里·辛顿教授团队(SuperVision)**提交的结果,无疑是一枚重磅炸弹。
错误率15.3%。
这一数字,瞬间将错误率降低了10个百分点以上,是压倒性的胜利。
更令人震惊的是他们所使用的设备。
并非价值数十亿的大学超级计算机,而是_仅用了两个消费级GPU(GTX 580)运行了6天所取得的成果_。
这一刻,后来被黄仁勋称为“AI的大爆炸”。

2. 黑暗时代:“猫”都认不出的超级计算机
让我们将时间拨回2012年之前。
当时的计算机视觉技术,主流是以依赖人类直觉的**“手工特征(Hand-crafted Features)”**方法。
“猫有尖耳朵。”
“眼睛是椭圆形的。”
“有胡须。”
研究人员们费尽心思试图用数学方法(如SIFT、HOG等)来定义这些规则。然而,现实是残酷的。
蜷缩的猫、只能看到背影的猫、藏在黑暗中的猫……面对人类未曾预设的变量,算法显得束手无策。
专家们称之为连接0和1的数字数据与真实概念之间无法逾越的鸿沟——“语义鸿沟(Semantic Gap)”。
就连谷歌也曾动用16,000个CPU核心进行猫脸识别实验,但成本效益却惨不忍睹。
英伟达也同样感到苦恼。
2006年,他们雄心勃勃地推出了允许GPU进行通用计算的CUDA平台,但却缺乏能充分发挥其潜力的“杀手级应用”。
市场只将他们视为“游戏配件公司”。
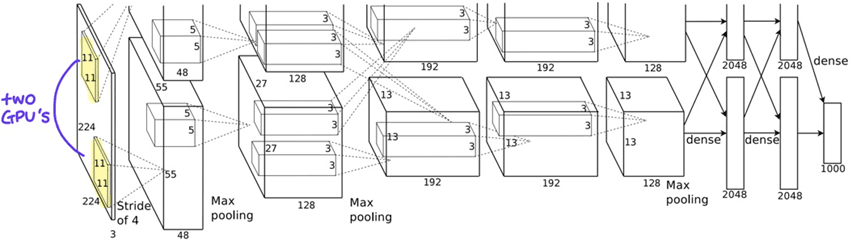
3. 匮乏催生的天才:超越3GB显存的限制
AlexNet的主要作者之一,亚历克斯·克里热夫斯基(Alex Krizhevsky)直觉地认为,**深度神经网络(Deep Neural Networks)**才是唯一的答案。
然而,计算量成为了一个巨大的挑战。这位贫困的研究生所拥有的“武器”,仅仅是实验室里闲置的两块GTX 580显卡。
由此,出现了一个历史性的“匮乏”。GTX 580的显存(VRAM)仅为3GB。
这对于一个拥有6000万个参数和65万个神经元的庞大神经网络来说,是远远不够的。
普通人可能会因为“设备不行”而放弃。但他们却将这一限制,升华为了工程上的天才之举。
“把大脑一分为二”
他们将神经网络一分为二,分别加载到两块GPU上。
这便是**分组卷积(Grouped Convolutions)和模型并行(Model Parallelism)**的雏形。
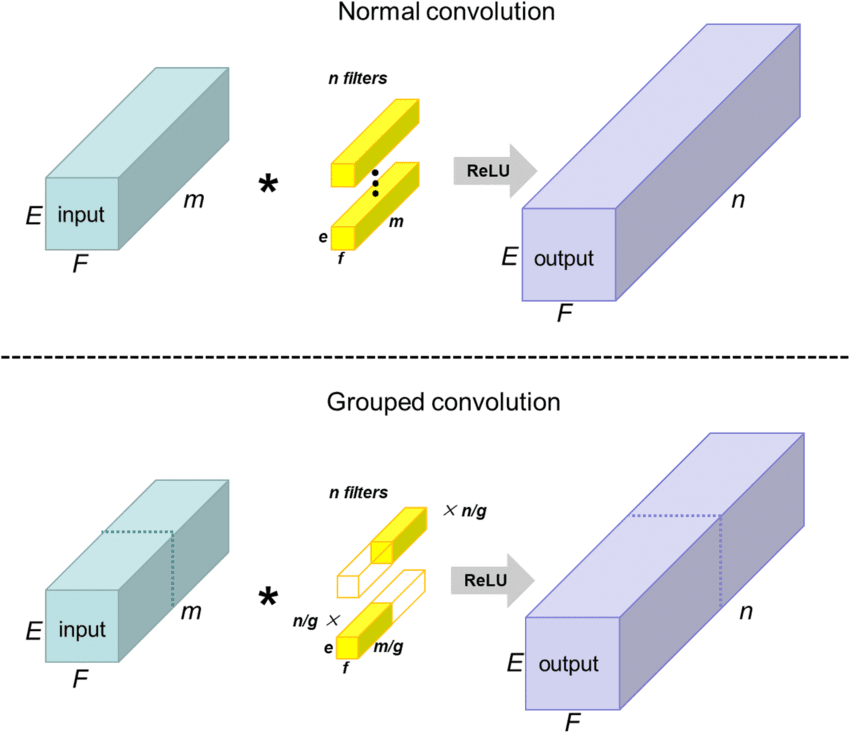
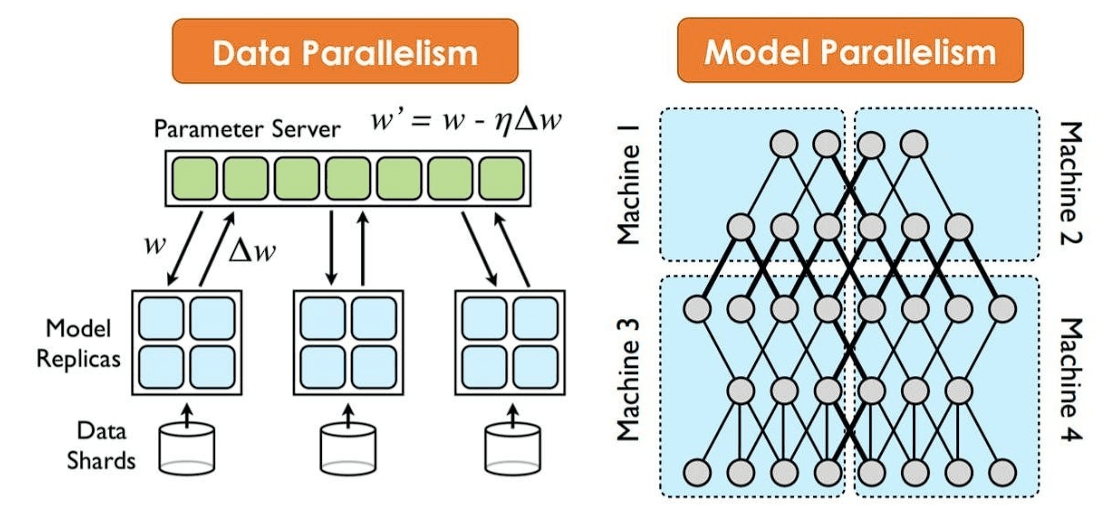
最大化并行处理: 两块GPU各自进行计算,仅在信息交换至关重要的层(Layer)才进行数据交换,最大程度地减少了通信瓶颈。
加速反馈: 将原本需要数月CPU训练的学习过程缩短至6天,使得他们能够进行疯狂的实验和迭代。
引入ReLU: 放弃复杂的函数,采用了极其简单的 $f(x)=max(0,x)$ ReLU函数,将学习速度又提高了6倍。
颇具讽刺意味的是,正是克服“显存不足”这一硬件限制的“技巧”,却为现代AI架构奠定了标准。
!(https://nvidianews.nvidia.com/flickr/images/72157714138767988/original.jpg ‘黄仁勋CEO宣布AI时代来临并发布路线图’)
{kind=link}
4. 黄仁勋的豪赌:“押上公司”(Bet the Company)

看到AlexNet的成功,英伟达CEO黄仁勋激动不已。
他本能地领悟到:
“未来的软件,将不再由人类编写,而是由数据来编写。”
1993年,他做出了一个决定,将英伟达的所有资源倾注于AI。
在公司内部,这被称为**“押上公司(Bet the Company)”**。
在当时,将盈利丰厚的游戏业务收入投入到尚不明朗的AI领域,无异于一场疯狂的赌博。
但他毫不动摇,主导了三项变革:
重新定义硬件: 将GPU架构从以图形渲染(绘图)为中心,彻底转变为以**矩阵运算(计算)**为中心。
构建生态系统(护城河): 免费发布cuDNN库,使研究人员无需了解硬件细节即可进行深度学习。这成为了**TensorFlow和PyTorch只能在英伟达平台上运行的强大护城河(Moat)**。
进化为系统公司: 2016年,他们制造了全球首台AI超级计算机DGX-1,并直接交付给OpenAI。这宣告了英伟达将从单纯的零部件供应商,转型为*‘AI基础设施公司’**。
5. 共进化(Co-evolution):软件塑造硬件
AlexNet问世后的十年,是软硬件完美双人舞(Pas de deux)的时代。
这被称为**“软件定义硬件(Software-Defined Hardware)”**。
随着AI模型的进化,芯片也随之进化。
Pascal (2016): 为了消除AlexNet时期遇到的通信瓶颈,开辟了NVLink高速通道。现在,8块GPU可以像一块巨大的芯片一样协同工作。
Volta (2017): 在芯片中植入了专门处理深度学习核心——矩阵乘法的*‘Tensor Core’**。
Hopper (2022) & Blackwell (2024): 为了支持Transformer和LLM,支持8位(FP8)、4位(FP4)运算,并极大地增加了内存带宽。
12年前还在为3GB显存发愁的技术,如今已经进化成搭载192GB HBM3e内存、吞吐数万亿参数的怪物(B200)。
6. 从玩家玩具到“智能工厂(AI Factory)”
这一系列技术进步,彻底改变了经济格局。
2012年市值仅为8万亿韩元的英伟达,到2025年已成为**4万亿美元(约合5500万亿韩元)**的企业。
更令人惊讶的是收入结构的转变。
过去,英伟达的主要收入来源是网吧和游戏玩家。
但如今,超过80%的收入来自数据中心。
亚马逊、谷歌、微软等公司正排队购买英伟达的GPU。
正如黄仁勋所言,数据中心已不再是数据的仓库,而是燃烧数据、生产“智能”这一全新商品的“AI工厂”。
在此过程中,SK海力士和三星电子也通过提供HBM(高带宽内存)这一高性能“燃料”,成为了这个庞大生态系统中不可或缺的合作伙伴。
7. 下一波浪潮:沉寂的物理引擎复活与“物理AI”
如今,英伟达正准备迎接超越AlexNet开启的“感知”时代,以及ChatGPT开启的“生成”时代,迎接新的战场——
即**“物理AI(Physical AI)”与机器人技术**。
在这里,我们看到了令人兴奋的技术的再利用。
或许一些怀旧的玩家会记得“PhysX”?
这是英伟达在2008年收购的一个物理引擎,它能让游戏中的墙壁破碎、斗篷飘动。
一度,它只被视为“让画面更漂亮”的附加功能。
然而,随着AI时代的到来,这项技术迎来了辉煌的复兴。
在现实世界中训练机器人,往往会导致摔倒和损坏。_因此,需要在虚拟空间(Sim-to-Real)中进行训练,这就需要一个能够完美模拟重力、摩擦和碰撞的模拟器_。
英伟达的机器人平台“Isaac”正是基于当年的游戏物理引擎技术,在虚拟世界中同时训练数千万台机器人。

20年前让玩家快乐的技术,如今已成为构建人形机器人小脑(Cerebellum)的核心基础设施。
8. 尾声:从感知到行动的智能
让我们来总结一下。
2012年AlexNet: 为计算机赋予了**“眼睛(Vision)”**。
2022年ChatGPT: 为计算机赋予了**“嘴巴(Language)”**。
未来的NVIDIA: 现在,正试图为计算机赋予“身体(Body)”。
从训练(Training)到推理(Inference),从虚拟智能到物理智能的旅程中,硬件与软件之间的激烈共生始终是核心。
如果当年GTX 580的显存更充足,会怎么样呢?
或许,“并行处理”这一革命性的想法就不会出现。
创新有时诞生于富足,但更多时候,它在**“克服匮乏的艰苦尝试”**中,闪耀出最耀眼的光芒。
我们如今正身处那份匮乏所创造的4万亿美元烟花的中心。
下一道火花,将从何处迸发?也许,它就藏在另一个人的“匮乏”之中。
参考资料
-
ImageNet Classification with Deep Convolutional Neural Networks [AlexNet论文]
-
NVIDIA: The Complete History and Strategy [Acquired Podcast]
-
Jensen Huang on the future of physical AI and robotics [The Economist]
-
The Intelligent Industrial Revolution: How AI Transforms Manufacturing [NVIDIA Blog]