这篇关于“AI主权”的文章,探讨了在人工智能时代,我们应该如何掌握自己技术命运的重要性。
海牙敲响警钟
我是技术分析师,用人文的视角审视技术。今天,我想和大家聊一个可能有点严肃,但却关系到我们和下一代未来的话题:“AI主权”。
你有没有想过这样的场景?有一天,我们每天工作的电子邮件,存储文档的云服务,突然因为“地球另一端某个国家的政策”而无法访问。你觉得这是科幻电影里的情节?

令人惊讶的是,这在2023年真实发生了。荷兰海牙国际刑事法院(ICC)的检察官们,就遇到了他们每天使用的微软(MS)云服务突然被切断的尴尬情况。他们正在调查俄罗斯战争罪行的工作,险些因此瘫痪。原因是什么?美国政府将ICC列入制裁名单,作为美国企业的MS,为了遵守本国法律,便中断了服务。
这一事件让全球政策制定者们不寒而栗。我们把所有数据都交给大型外国企业服务器,只是为了换取便利,这是多么危险的事情。技术依赖如何能在一瞬间侵蚀我们的主权,这个事件赤裸裸地展示了这一点,是一个令人震惊的案例。
而这种冰冷的恐惧,如今正以人工智能(AI)时代的前所未有的巨浪,向我们袭来。如果说云服务中断只是切断了一个部门的补给线,那么AI的依赖则相当于将国家的中枢神经系统拱手相让。
第一章:发现新大陆:“基础模型”——AI时代操作系统
你可能对GPT、Gemini这些词耳熟能详。这些超大型AI模型,在技术上被称为**“基础模型(Foundation Model)”**。顾名思义,它们是AI生态系统的“基础”,是万物起点的模型。
这为什么如此重要?让我们乘坐时光机回到过去的IT时代。
- 20世纪80年代,PC时代: 许多公司想在PC上开发程序,而让这一切成为可能的是微软的“Windows”。微软凭借其操作系统(OS)的统治地位,制定了PC时代的一切规则,并从那些在其上销售软件的公司那里获得了巨额财富。
- 21世纪初,智能手机时代: 谷歌的“Android”和苹果的“iOS”成为了新的操作系统。无论我们开发多么有创意和出色的App,最终都必须在谷歌和苹果设定的应用商店里,遵循它们制定的收费政策(也就是“过路费”)才能发布。
是的,基础模型正是**“AI时代的操作系统”**。
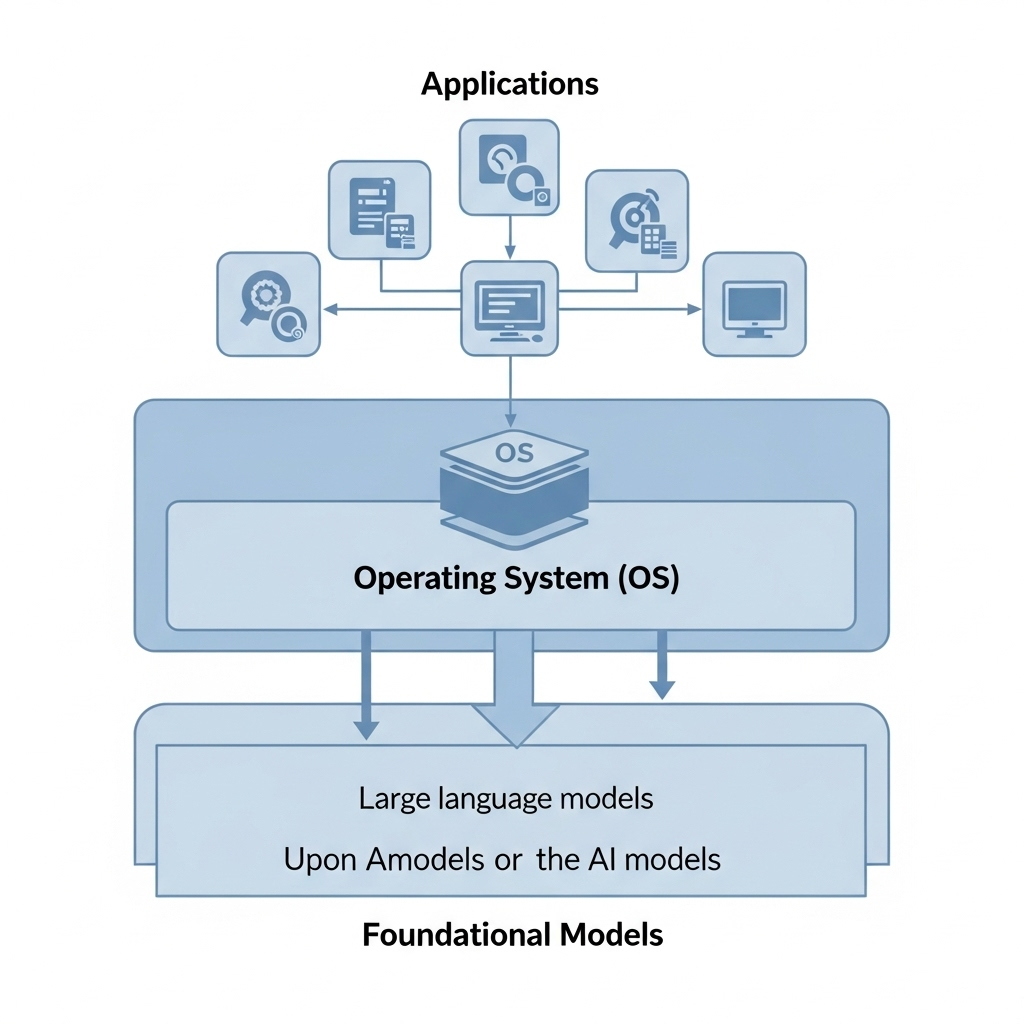
过去,操作系统统治着PC和智能手机这些“数字领土”。而基础模型则像巨大的吸尘器一样,吸纳全球的文本、图像、视频数据,学习人类的所有知识,并在其之上构建新的“AI领土”。这个领土上的所有规则和秩序,都由拥有领土的“地主”来决定。
问题在于,这片广袤的新大陆的大部分,已被美国和中国的科技巨头——如谷歌、微软、OpenAI、Meta,以及百度、腾讯等——牢牢占领并垄断。用韩国hanbitmedia公司的朴泰雄会长的话来说,我们正面临着一个悲惨的局面:我们只能旁观AI新大陆的发现,最终却只能在他们划定的地界内“租地耕种”,成为**“佃农”**。
第二章:“借用不行吗?”:甜蜜诱惑背后的三种毒药
这时,很多人会提出一个非常合理的问题:
“既然已经有这么好的模型了,我们为什么要花费巨额资金和人力去重新开发呢?直接通过API借用,不是更有效率、更经济吗?”
没错。这是一个非常合乎情理的问题。就像造汽车不必自己建轮胎厂一样。但是,“AI引擎”——基础模型,它并非简单的零部件。其中隐藏着我们绝不能忽视的三个致命陷阱。
第一,安全:插在心脏上的数字匕首
再次回想一下前面提到的ICC案例。如果那不是一个国际组织,而是我们的国防部、国家情报院,甚至是核电站呢?
想象一下,我们将我们敏感的军事作战计划、与核心盟友交换的外交机密、国民的医疗记录和金融信息、国家关键基础设施的设计图等数据,放在外国企业的基础模型上处理。这些数据的最终控制权,真的在我们手里吗?在国际局势急剧变化的紧急情况下,我们能百分之百保证,他们不会为了自身利益而停止服务,甚至不会分析我们的数据来攻击我们,将其作为**“数字匕首”**吗?
就像美国通过控制半导体设备出口来施压竞争对手一样,未来**“AI模型访问权”**将成为最强大的外交武器。如果我们手中没有保卫我们的“AI引擎”,我们将只能被动地暴露在国家命运受其决定摆布的境地。
第二,文化:扭曲的镜子中的我们
更微妙、更可怕的问题是文化和语言上的依赖。
绝大多数的全球基础模型,是以英语为中心,用美国和西方的数据训练的。当我们问他们“独岛是哪个国家的?”时,他们会回答“独岛是韩日之间存在领土争议的地区(Liancourt Rocks is a disputed territory…)”,这对于我们来说是无法接受的答案。他们只是根据自己学习到的数据,给出最“概率上正确”的答案而已。
这仅仅局限于独岛问题吗?我们的历史、民主进程、社会价值观,以及韩语特有的微妙细致的语境(例如,“情”、“恨”、“眼力”)能够完全理解和反映的AI,只有用我们的数据、用我们自己的双手创造的AI。
将教育、媒体和内容创作依赖于外国AI,无异于给我们的孩子**“一本被外国人视角歪曲的历史教科书”。我们的身份认同,将在他们创造的“扭曲的镜子”中逐渐失去光彩。就像搜索引擎改变了我们的知识获取方式一样,AI将动摇我们的思维方式和价值观本身。如果我们在这场无声的战争中失去主权,我们将从经济殖民地沦为“文化和精神殖民地”**。
第三,经济:永恒的“数字佃农”枷锁
这是最现实的问题。如果我们没有自己的基础模型,也就是“AI引擎”,而一直借用外国的引擎,我们就永远无法摆脱需要支付高昂授权费的“技术佃农”的命运。
我们已经看到了智能手机App开发者,将30%的收入作为“应用商店手续费”交给谷歌和苹果。在AI时代,这种依赖将进一步加剧。未来的所有产业——金融、医疗、法律、制造、内容——都将基于AI实现创新。但是,如果创新心脏植入了不属于我们的引擎,会怎么样?
无论我们开发出多么出色的AI服务,这些服务创造的绝大部分价值,都将以引擎使用费的名义,持续进贡给美国和中国的“技术地主”。这就像我们在肥沃的土地上拼命耕作,但大部分收成都被地主剥夺的佃农的处境一样。所有产业的利润,都会被掌握AI引擎的少数全球科技巨头吸收,形成“数字地租经济”的结构。这正是**“数字殖民地”**的实质。
第三章:荆棘之路:迈向“我们自己的引擎”的四个巨大障碍
在这种迫切的需求下,“主权AI(Sovereign AI)”的概念应运而生。即,我们的数据,在我们的领土内,遵循我们的法律和规定,用我们自己的双手创造的AI来处理。而实现主权AI的关键,也就是“AI时代的钥匙”,是拥有“我们自己的基础模型”。
最近,韩国政府任命了引领Naver的“HyperCLOVA X”和LG的“EXAONE”开发的两位专家担任AI政策最高负责人,这正是对这种时代紧迫感的明确回应。这表明了“不再借用,我们要制造我们自己的AI引擎,构建我们自己的AI领土”的强烈决心。
这并非简单地模仿美国或中国的“追赶者战略”。在AI这个巨大的文明浪潮面前,我们正以**“技术独立宣言”**的方式,决定我们自己的命运。
当然,这条道路绝非坦途。我们面前有重重巨大的障碍。

- 第一,资本之山:需要天文数字般的“弹药”。 一次训练超大型AI模型需要巨额的成本。需要数万个最新的GPU(图形处理器)连续运行数周甚至数月。英伟达最新的AI芯片“Blackwell”每颗就高达4万美元(约合5500万韩元)。 확보数万颗这样的芯片,建设数据中心,消耗巨额电力的成本加起来,需要数万亿韩元的“弹药”。谷歌、微软等企业依靠其庞大的现金流参与这场竞争,但这对我们的企业和政府来说,规模过于庞大。
- 第二,数据之山:缺乏“高质量的韩语数据”。 AI模型的性能最终取决于学习数据的数量和质量。全球网络数据中,英语占据了绝大部分比例。相对而言,韩语数据不仅量少,而且要 확보不受版权问题困扰、不带偏见的“高质量数据”,则更加困难。特别是法律、医疗、金融等专业领域的特化数据,系统地构建和净化,是需要国家层面努力的巨大课题。
- 第三,人才之山:“AI大脑”争夺战。 目前,全世界正在进行一场没有硝烟的战争,争夺顶尖的AI研究者和开发者。全球科技巨头们向硅谷的顶尖人才提供数十亿韩元的年薪和股票期权,组建“AI梦之队”。我们真的能在与他们的挖角竞争中占据优势吗?我们必须冷静审视,国内大学的AI教育体系和企业的研发环境,是否足够吸引他们留下。
- 第四,认知之山:跨越“短期效率”的陷阱。 也许最难逾越的山,是我们内部的“认知”。从只顾眼前效率和经济性的短期角度来看,“直接借用就好”的论调总是显得更加合理。也存在“我们又不是半导体,怎么连AI都要自己做?”的冷嘲热讽。说服国民和政策制定者,达成社会共识,推广“AI主权”这一长期战略性价值,其过程可能和技术开发一样艰难。
第4章. 韩国的指南针:我们应该做什么,怎么做?
面对这四个巨大的挑战,我们是否只能感到沮丧和放弃?不。我们有自己的方法,有最擅长走的道路。我们有在20世纪70年代,在人们普遍认为不可能的贫瘠土地上,建造半导体工厂、制造汽车发动机并创造奇迹的坚韧力量。
在人工智能时代,韩国的指南针应该指向何方?
第一,瞄准“最优”,而非“最强”的“强小国AI战略”
如果我们现在就尝试制造比GPT-5更庞大的通用模型,那可能会显得鲁莽。在资本和数据规模上追赶谷歌和微软,在现实中是困难的。但我们拥有“选择和集中”这一明智的策略。
我们的目标不是做一个“无所不能”的AI,而是要制造专注于我们最擅长领域的“专家AI”。我们将所有力量投入到世界顶级的制造业、半导体、医疗以及K-文化内容领域,建立一个在该领域无人能敌的“垂直主权AI”战略。例如,可以开发优化半导体设计和良率管理的AI,基于韩国人基因信息和医疗记录的精准医疗AI,以及能俘获全球K-pop粉丝喜好的内容生成AI。小而精,性能强大,这才是我们应该走的道路。
第二,组建“Team Korea”:汇聚政、产、学各方力量
AI引擎的开发已经不再是单个企业能独立完成的“国家级竞赛”。政府不应纠结于短期成果,而应着眼于未来10年、20年,通过持续的研发投入和大胆的法规创新,为企业创造一个能自由驰骋的“赛场”。大学应成为培养能立即投身产业一线的关键人才的“人才摇篮”。而像Naver、Kakao、LG、SKT、KT这样的大企业,在各自开发模型、相互竞争的同时,也应在国家级数据基础设施建设或人才培养等共同目标面前,展现出“一个团队”的精神,团结协作。
第三,建设“数据粮仓”:储备AI时代的原油
如果说AI的性能取决于数据,那么我们就应该在全国各地系统地收集、提炼并安全利用分散的优质公共和产业数据,建设“国家数据粮仓”。当然,个人信息保护和数据安全是首要原则。但以“安全”为借口,将所有数据紧锁起来,无异于因噎废食。当务之急是改革法律法规,达成社会共识,以便能安全地、去标识化地利用数据进行AI学习。
21世纪,如果我们不能建造我们的“AI工厂”
20世纪,我们忍饥挨饿,修建京釜高速公路,点燃浦项制铁的熔炉,建造半导体工厂,这是为何?那是因为我们不愿将贫困和被支配的历史留给后代,是“命运由我们自己决定”这种悲壮的独立意志的体现。

21世纪,那段激烈产业化时代的战场,已经转移到了“AI领土”。我们亲手建造“AI工厂”,用我们的技术制造“AI引擎”,这与过去修建高速公路、建造制铁厂具有完全相同的分量和意义。
AI主权不再仅仅是技术专家的讨论或选择问题。这是决定我们和我们的孩子在即将到来的未来,能否作为堂堂正正的**“数字主权国家”**的国民,而不是“数字殖民地”的国民而生存下去的问题。
我们亲手制造的AI引擎强劲跳动着的未来,就是我们应该共同创造的韩国的模样。这条道路无疑会艰辛而崎岖,但我们一定能再次做到。