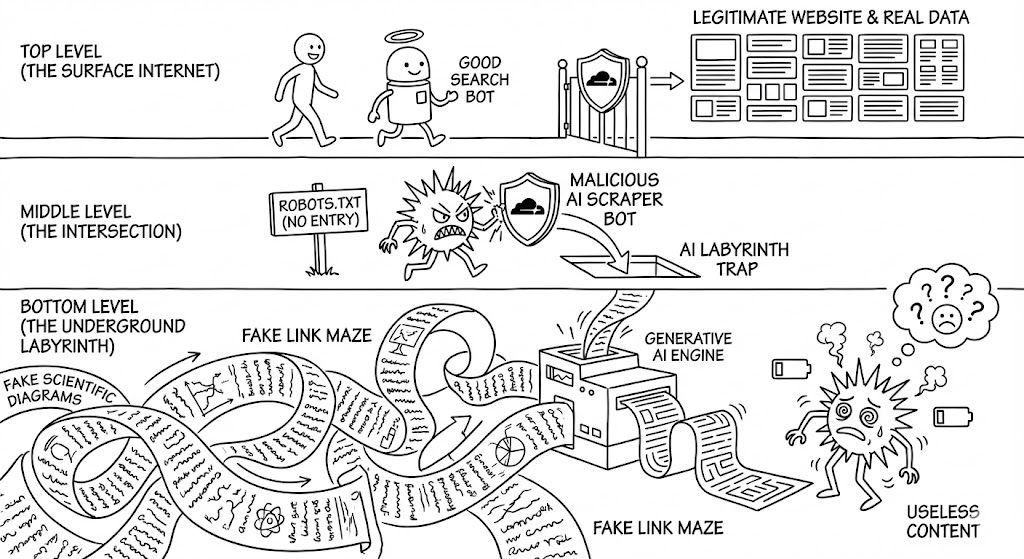
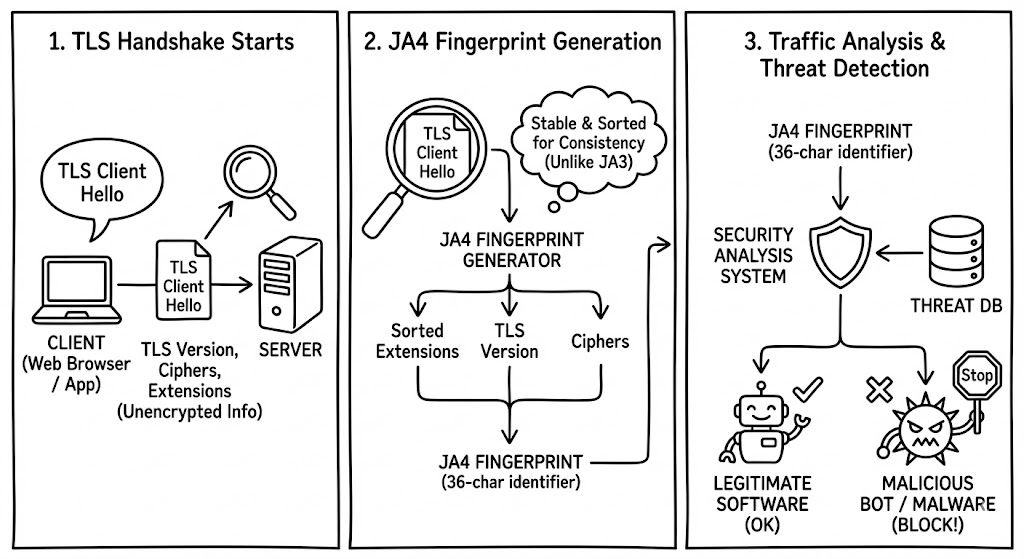
주거용 프록시(Residential Proxies): 봇들은 해킹된 가정용 공유기, 스마트 냉장고, CCTV 등을 경유해서 접속합니다. 방어 시스템 입장에선 평범한 가정집에서 접속하는 것처럼 보이니 차단하기가 매우 까다롭습니다. 당신의 스마트 냉장고가 지금 이 순간, **AI의 데이터 도둑질을 돕는 ‘좀비’**가 되어 있을지도 모릅니다.
AI 캡챠 솔버(CAPTCHA Solver): “로봇이 아닙니다"를 체크하는 퍼즐은 이제 무용지물입니다. 최신 AI는 사람보다 퍼즐을 더 잘 풀며, 심지어 마우스 커서를 **사람처럼 비틀거리며 움직이는 ‘인간 코스프레’**까지 완벽하게 학습했습니다.
2.3. 픽셀 전쟁: 나이트셰이드(Nightshade)
데이터 자체에 독을 타는 기술도 등장했습니다.
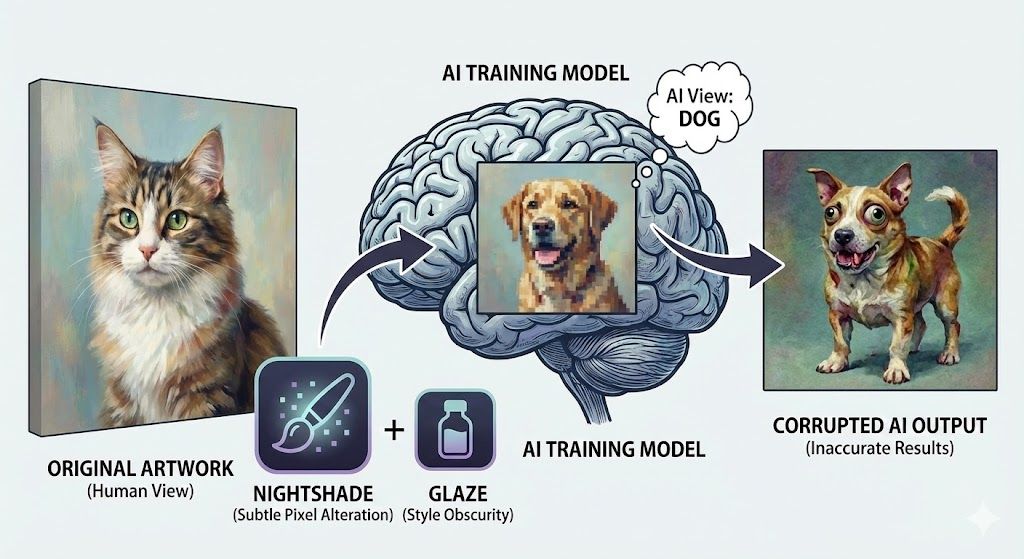
시카고 대학이 개발한 **‘나이트셰이드(Nightshade)’**는 이미지에 인간의 눈에는 절대 보이지 않는 미세한 노이즈를 섞습니다.
Nightshade (Software)
이 그림을 AI가 학습하면 끔찍한 일이 벌어집니다.
AI는 ‘고양이’ 그림을 ‘강아지’로 인식하고, ‘핸드백’을 ‘토스트기’로 착각하게 됩니다.
_훈련 데이터가 오염되어 모델 전체가 망가지는 **‘모델 중독’**을 유발하는 것_입니다.
예술가들이 자신의 작품을 지키기 위해 스스로 데이터에 ‘독약’을 뿌려야만 하는 아이러니한 시대, 이것이 바로 2025년의 풍경입니다.
3. 경제적 붕괴: 레몬 시장과 모델의 치매
왜 이렇게까지 처절하게 싸워야 할까요?
근본적인 원인은 AI 데이터 시장이 급속도로 **‘레몬 시장(Market for lemon)’**으로 변질되고 있기 때문입니다.
Market for lemon
3.1. 쓰레기가 쓰레기를 낳다
경제학에서 ‘레몬’은 겉만 번지르르하고 속은 썩은 불량품을 뜻합니다.
지금 인터넷은 AI가 쓴 영혼 없는 글과 그림으로 뒤덮이고 있습니다.
가장 큰 문제는 **‘무엇이 사람이 만든 것인지 구별할 수 없다’**는 점입니다.
결국 진짜 사람이 쓴 고품질 정보(논문, 심층 에세이)는 유료 벽(Paywall) 뒤로 꽁꽁 숨어버리고, 무료 웹에는 AI가 쏟아낸 스팸성 콘텐츠만 남게 됩니다.
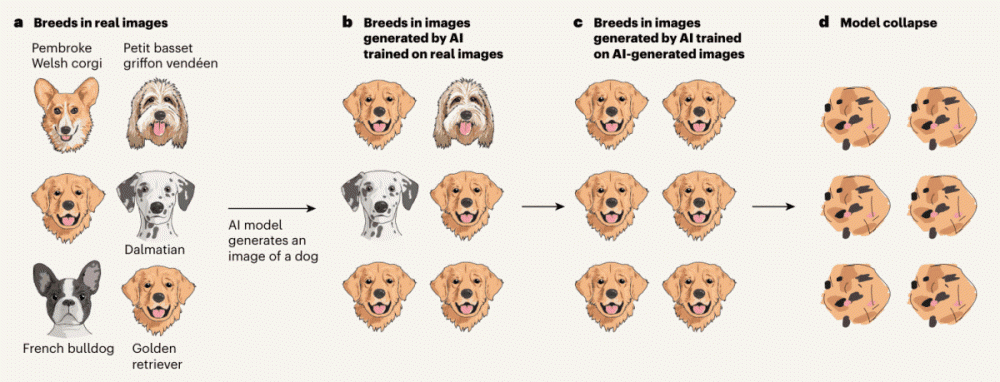
3.2. 모델 붕괴(Model Collapse): AI의 근친교배
더 무서운 건 ‘모델 붕괴’ 현상입니다. 이를 수식으로 표현하면 다음과 같습니다.
$$S\_{t+1} = \\alpha D\_0 + (1-\\alpha) D\_t$$
(여기서 $D\_0$는 순수 인간 데이터, $D\_t$는 AI가 생성한 데이터입니다.)
복잡해 보이지만 핵심은 간단합니다.
model collapse
AI가 다른 AI가 만든 데이터를 다시 학습하면 어떻게 될까요?
마치 생물학적 근친교배처럼 유전적 다양성이 사라집니다.
창의적이고 독특한 표현은 멸종하고, 뻔하고 평균적인 대답만 하는 **‘멍청한 AI’**가 되어버립니다.
연구에 따르면, 불과 5세대 정도만 반복해도 AI는 현실과 동떨어진 헛소리를 하기 시작합니다. 이를 **‘AI 치매’**라고도 부릅니다.
이 때문에 2023년 이전, 즉 생성형 AI가 폭발하기 전에 사람이 작성한 **‘빈티지 데이터(Vintage Data)’**의 가격이 천정부지로 치솟고 있습니다.
마치 방사능에 오염되지 않은 ‘핵실험 이전의 강철’처럼 말입니다.
4. 파편화된 세계: 스플린터넷(Splinternet)의 도래
이 전쟁은 이제 기업을 넘어 국가 간의 규제 전쟁으로 확산되며 인터넷을 산산조각 내고 있습니다.
이를 **‘스플린터넷(Splinternet, 쪼개진 인터넷)’**이라고 합니다.
splintenet
미국 (법정의 전쟁터): 뉴욕타임스가 오픈AI를 고소한 사건이 상징적입니다. **“내 기사를 훔쳐 돈을 벌지 마라”**는 주장과 **“공정 이용(Fair Use)”**이라는 주장이 팽팽합니다.
유럽연합 (규제의 요새): 세계에서 가장 강력한 ‘AI 법(AI Act)‘을 통해 투명성을 요구합니다. “어떤 데이터를 썼는지 낱낱이 밝혀라"라고 압박하며, 규제를 못 지키는 AI 기업은 진입조차 막습니다.
일본 (학습의 낙원): 정반대입니다. **“저작권 걱정 말고 마음껏 학습하라”**며 세계에서 가장 느슨한 법을 적용 중입니다. 전 세계 AI 기업들을 유치하기 위해 스스로 ‘데이터 피난처’를 자처하고 있습니다.
5. 미래 전망: 수렵 채집에서 농경 사회로
우리는 지금 정보 혁명의 중대한 변곡점을 지나고 있습니다.
앞으로의 웹은 크게 두 가지 세상으로 나뉠 것입니다.
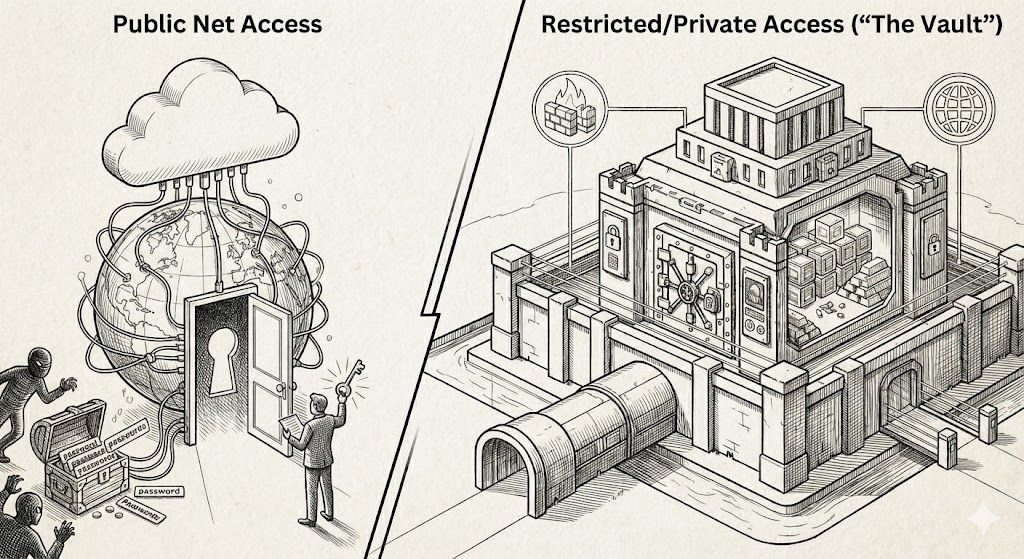
공공 웹 (Public Web): 누구나 볼 수 있지만, AI가 만든 저품질 정보와 광고가 쓰레기장처럼 넘쳐나는 곳.
금고 웹 (The Vault): 사람이 검증한 고품질 정보가 있는 곳. 이곳에 들어가려면 생체 인증을 하거나 돈(HTTP 402)을 내야 합니다.
public web vs the vault
새로운 권력: 데이터 노동조합과 인간 증명
이 변화 속에서 새로운 형태의 조직이 탄생할 것입니다.
DataDAOs
데이터 노동조합 (DataDAOs): 개인의 힘은 미약하지만 뭉치면 강합니다. 개인의 데이터를 한데 모아 거대 AI 기업과 협상하고, 그 수익을 암호화폐로 나눠 갖는 **‘디지털 노동조합’**이 등장할 것입니다.
인간 증명 (Proof of Personhood): 미래의 가장 큰 비즈니스는 **“나는 봇이 아니라 진짜 피가 흐르는 인간입니다”**를 증명하는 서비스가 될 것입니다. 클라우드플레어나 월드코인 같은 기업들이 이 ‘디지털 신분증’을 발급하는 막강한 권력을 쥐게 될 것입니다.
Proof of Personhood
결론: 공짜 점심은 끝났다
클라우드플레어가 쏘아 올린 신호탄은 단순한 보안 업데이트가 아닙니다.
그것은 **“데이터는 더 이상 공공재가 아니라 자산이다.”**라는 거대한 선언입니다.
우리는 그동안 인터넷이라는 숲에서 마음껏 정보를 따먹는 ‘수렵 채집인’이었습니다.
하지만 이제 숲에는 울타리가 쳐졌습니다.
우리는 정보를 경작하고, 관리하고, 정당한 값을 지불해야 하는 **‘농경 사회’**로 강제 진입하고 있습니다.
이 변화가 불편할 수도, 정보 격차를 벌릴 수도 있습니다.
하지만 어쩌면 이것은 AI의 무한 복제 속에서 **‘인간의 창의성’**이라는 희소자원의 가치를 지키기 위한 필연적인 과정일지도 모릅니다.
이제 마지막으로 여러분에게 묻고 싶습니다.
당신이 오늘 인터넷에 남긴 생각 한 조각, 그 가치는 과연 얼마입니까?
참고자료
1 Cloudflare Blog: To build a better Internet in the age of AI, we need responsible AI bot principles (Easton & Zaheri, 2025) \[Link\]
2 Cloudflare Blog: Introducing pay per crawl: Enabling content owners to charge AI crawlers for access (Kresh & Vcelak, 2025)
\[Link\]
3 GBHackers: Cloudflare Reveals AI Labyrinth to Counter Automated AI Attacks (Gurumoorthy, 2025)
\[Link\]
4 DEV Community: Cloudflare’s JA4 Fingerprinting: Smarter Threat Detection Through TLS (Tech Analysis, 2025)
\[Link\]
5 University of Chicago: Protecting Copyright - Nightshade & Glaze Project (Sandwich et al., 2025)
\[Link\]
6 Nature: The AI Echo Chamber: Model Collapse & Synthetic Data Risks (Shumailov et al., 2024)
\[Link\]
7 New York Times: OpenAI resists court order to share ChatGPT logs with NYT (Legal Report, 2025)
\[Link\]
8 European Parliament: ‘Splinternets’: Addressing the renewed debate on internet fragmentation (Research Service, 2022)